> ## Documentation Index
> Fetch the complete documentation index at: https://docs.dify.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Web サイトからデータをインポート
> このドキュメントは AI によって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/cloud/use-dify/knowledge/create-knowledge/import-text-data/sync-from-website) を参照してください。
Dify のナレッジベースでは、[Jina Reader](https://jina.ai/reader)や[Firecrawl](https://www.firecrawl.dev/)を利用してウェブページをスクレイピングし、解析したデータを Markdown の形式でナレッジベースに取り込むことができます。
[Jina Reader](https://jina.ai/reader) や [Firecrawl](https://www.firecrawl.dev/) は、オープンソースのウェブページ解析ツールです。ウェブページをクリーンで大規模言語モデル(LLM)が扱いやすい Markdown 形式のテキストに変換します。また、使いやすい API サービスも提供しています。
## Firecrawl
### Firecrawl の認証情報の設定
右上隅にあるアバターをクリックし、DataSource ページで Firecrawl の認証情報を設定する必要があります。
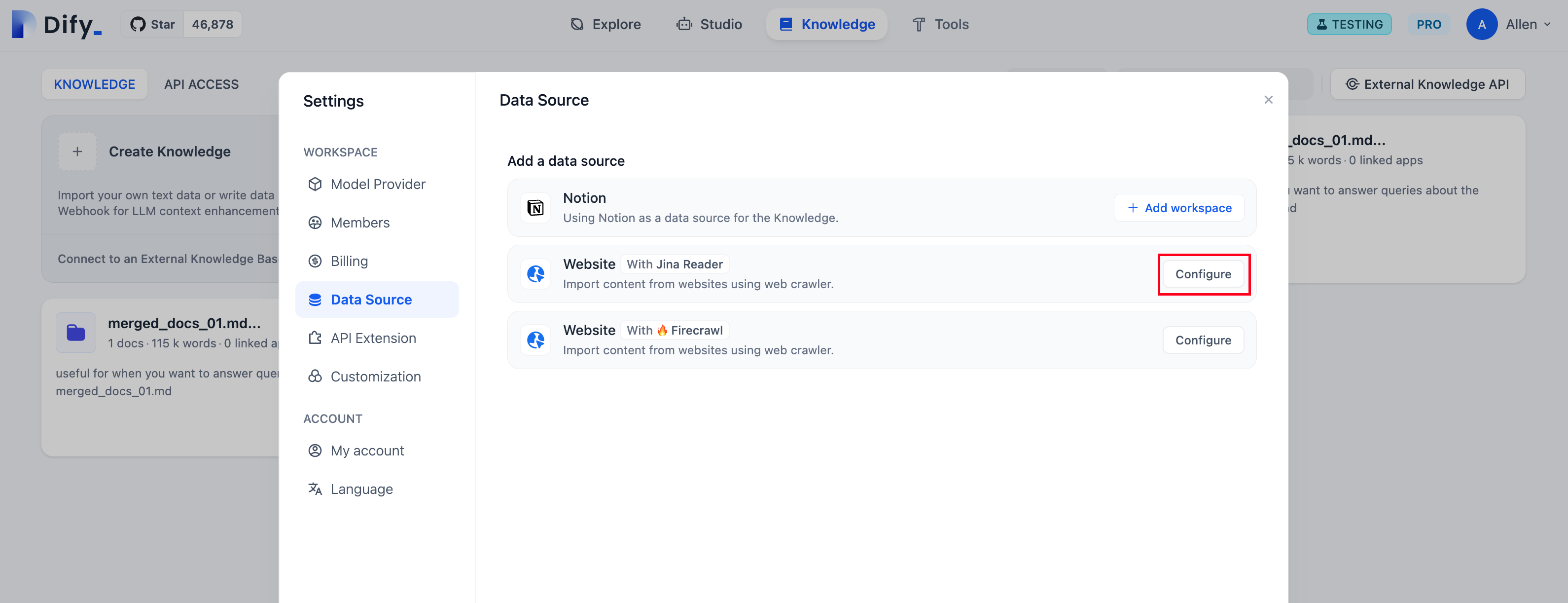
[Firecrawl 公式サイト](https://www.firecrawl.dev/) にログインして登録を完了し、API キーを取得してから入力し、保存します。
### Firecrawl を使用して Web コンテンツをクロールする
ナレッジベース作成のページで **Sync from website** を選択し、スクレイピングの対象どしてのウェブページの URL を入力します。
設定項目には、サブページのスクレイピング、スクレイピングするページの上限、ページのスクレイピング深度、ページの除外、指定ページのみのスクレイピング、コンテンツの抽出などが含まれます。設定が完了したら **Run** をクリックし、解析結果のページをプレビューします。
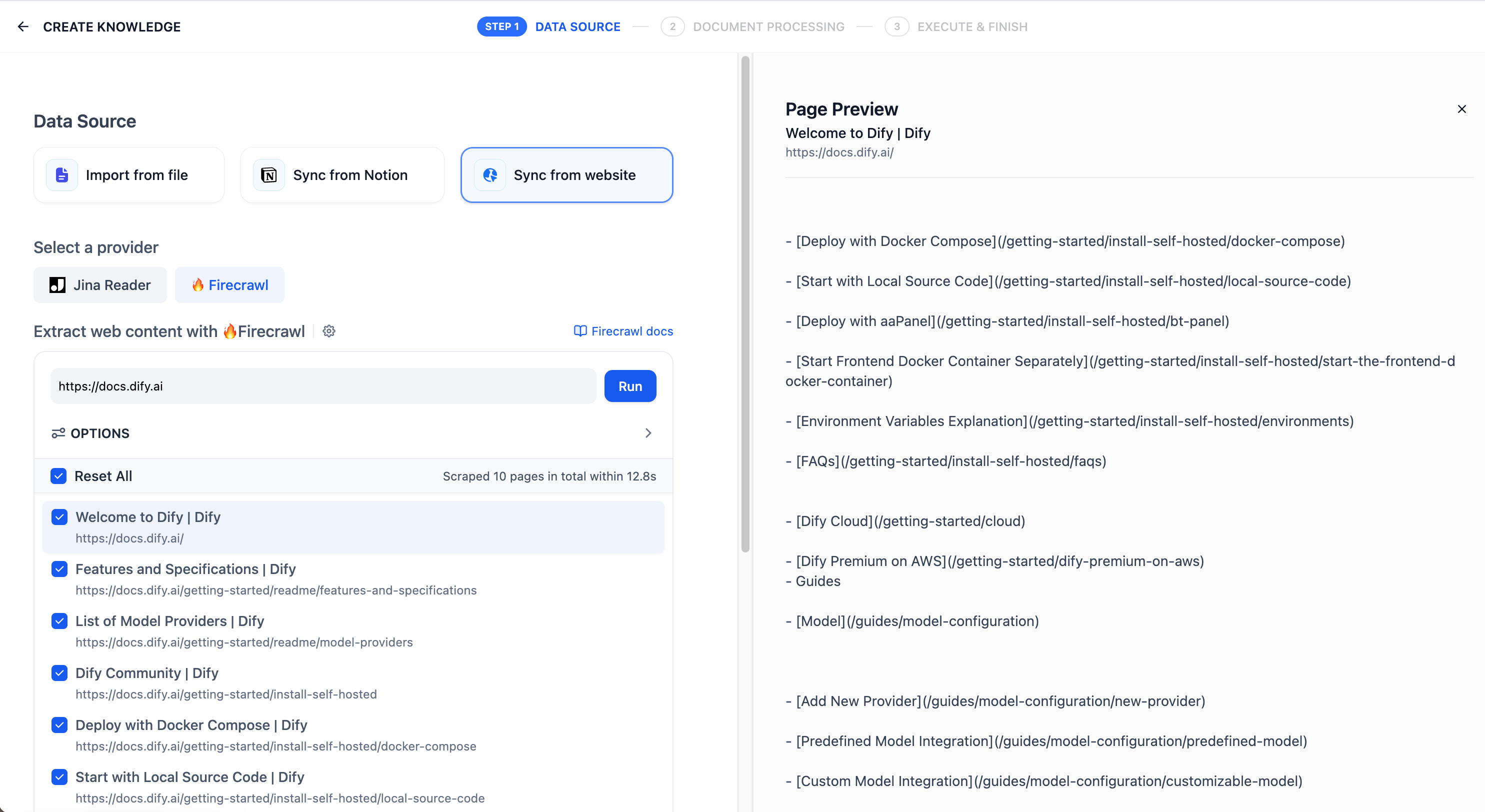
解析されたテキストをナレッジベースのドキュメントにインポートし、結果を確認します。**Add URL** をクリックすると、新しいウェブページをさらにインポートできます。
## Jina Reader
### Jina Reader の認証情報の設定
右上隅にあるアバターをクリックし、DataSource ページで Jina Reader の認証情報を設定する必要があります。

[Jina Reader の公式サイト](https://jina.ai/reader) にログインして登録を完了し、API キーを取得してから入力し、保存します。

### Jina Reader を使用して Web コンテンツをクロールする
ナレッジベース作成のページで **Sync from website** を選択し、スクレイピングの対象どしてのウェブページの URL を入力します。
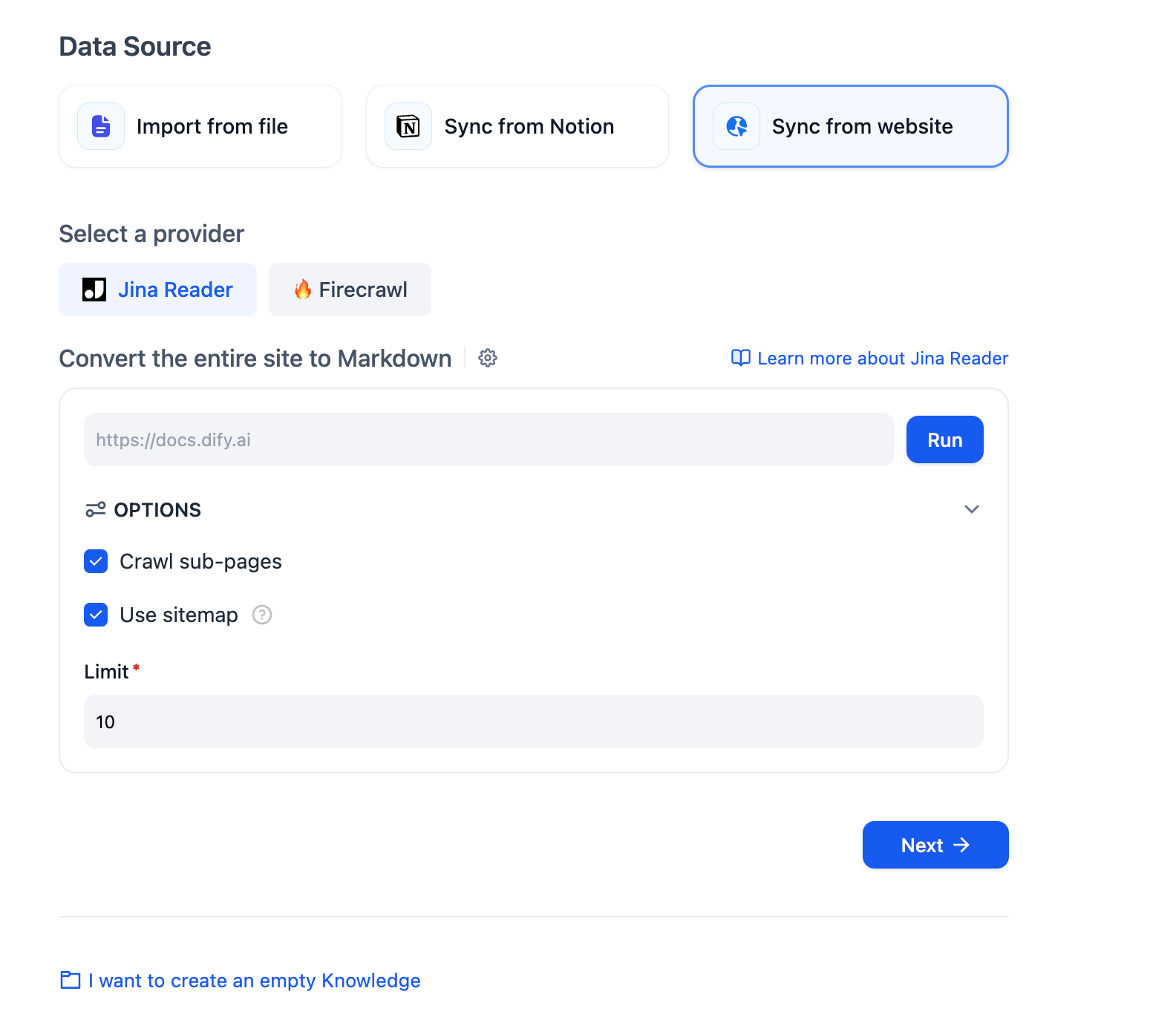
設定項目には、サブページをクロールするかどうか、クロールされるページ数の上限、サイトマップのクロールを使用するかどうかなどがあります。設定が完了したら **Run** をクリックし、解析結果のページをプレビューします。
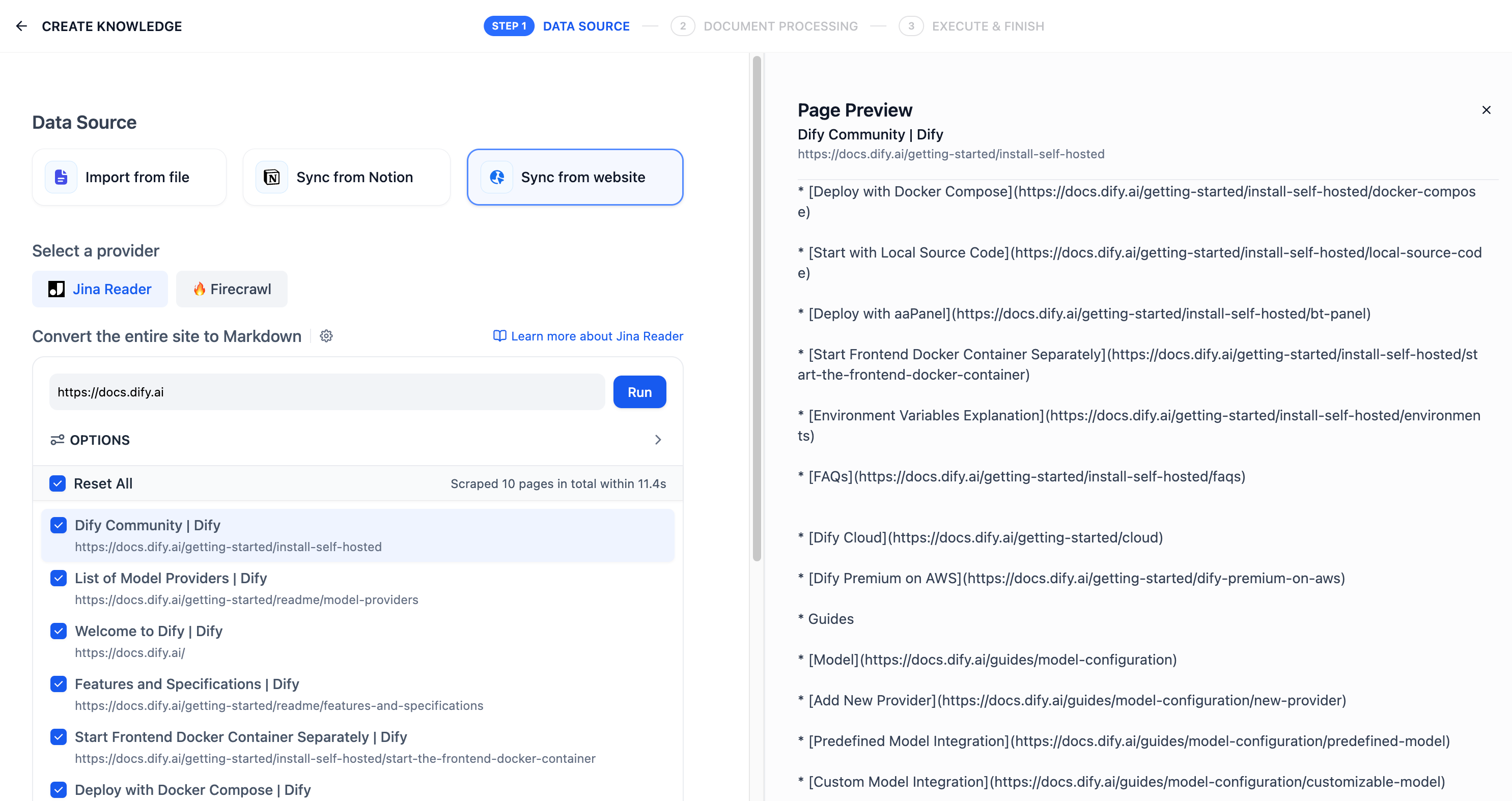
解析されたテキストをナレッジベースのドキュメントにインポートし、結果を確認します。**Add URL** をクリックすると、新しいウェブページをさらにインポートできます。
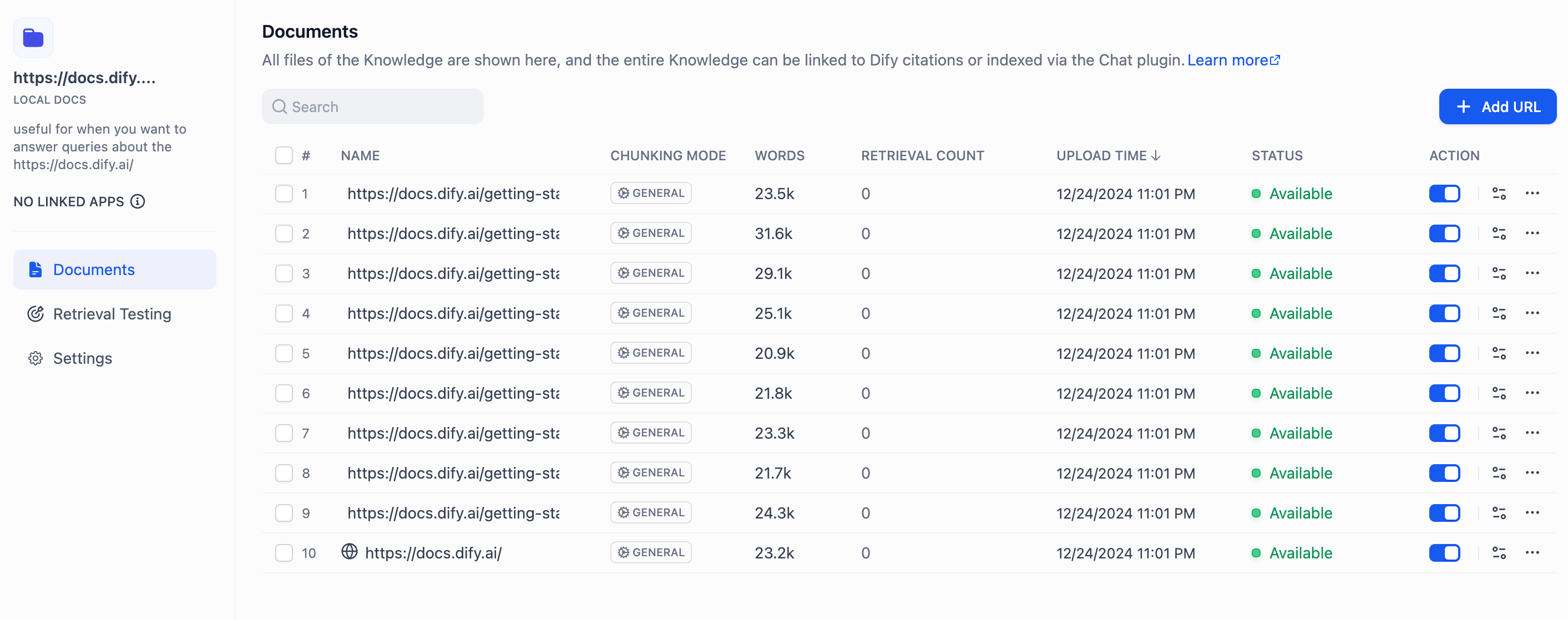
クロールが完了すると、Web ページのコンテンツがナレッジ ベースに組み込まれます。