**エコノミー**
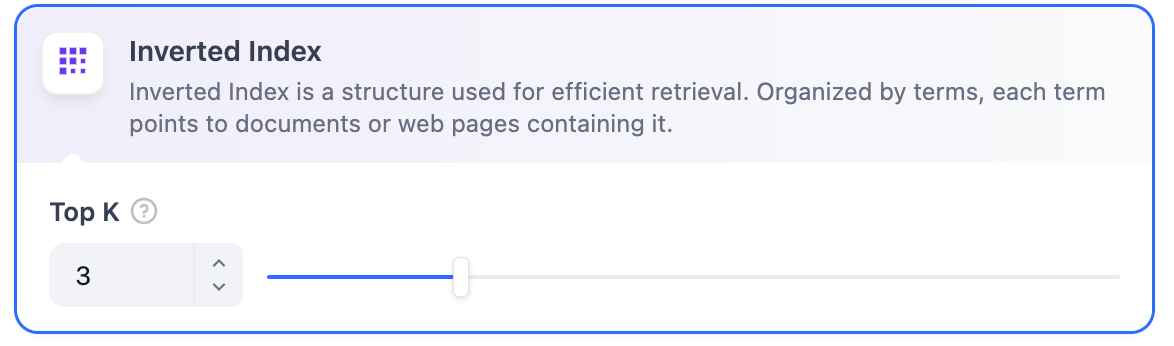
**エコノミーインデックス** モードでは、逆引きインデックスアプローチのみが利用可能です。逆引きインデックスはドキュメント内のキーワードを高速に検索するために設計されたデータ構造で、オンライン検索エンジンでよく使用されています。逆引きインデックスは**TopK** 設定のみをサポートしています。
**TopK**:ユーザーのクエリに最も類似していると判断されたテキストチャンクの取得数を決定します。選択したモデルのコンテキストウィンドウに基づいてチャンク数を自動的に調整します。デフォルト値は **3** で、値が高いほど多くのテキストチャンクが呼び出されます。