

⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考英文原版。
配置
输入和模型设置
输入变量 - 选择要分类的内容,通常是用户问题的sys.query,但也可以是来自之前工作流节点的任何文本变量。
模型选择 - 选择用于分类的大型语言模型。对于简单分类,速度较快的模型表现良好,而对于细致入微的区分,更强大的模型处理得更好。
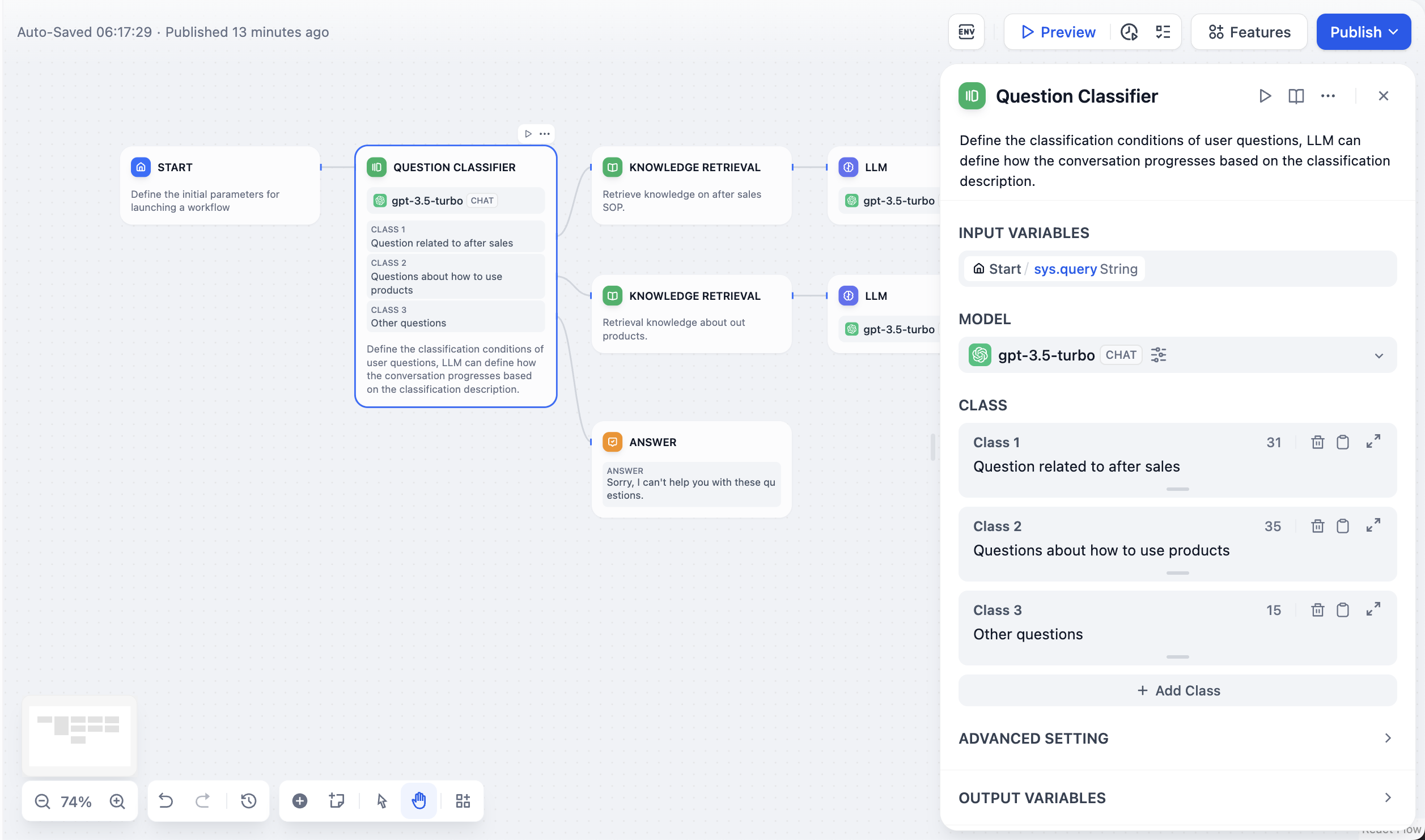
问题分类器配置界面
类别定义
为每个类别创建清晰、描述性的标签,并具体描述每个类别应包含的内容。明确类别之间的边界,以帮助大型语言模型做出准确决策。 每个类别都成为一个潜在的输出路径,你可以将其连接到不同的下游节点,如专门的知识库、响应模板或处理工作流。分类示例
以下是问题分类器在客户服务场景中的工作方式: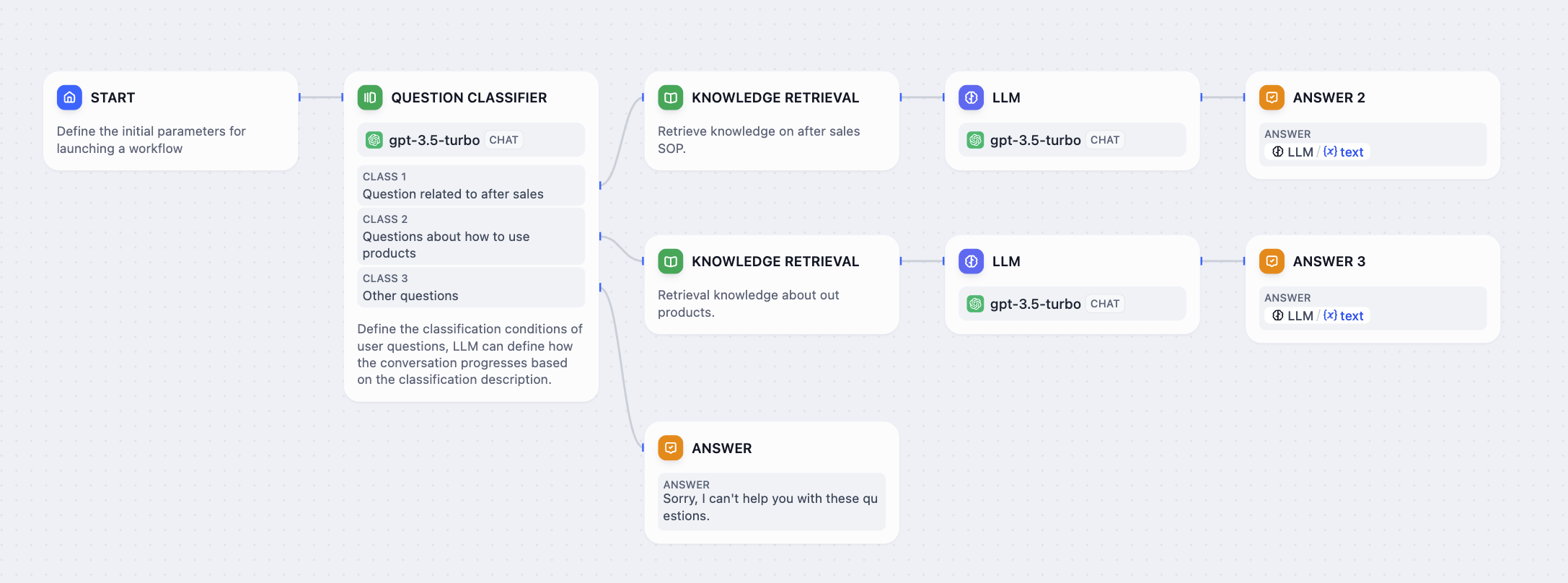
客户服务分类工作流
- 售后服务 - 保修申请、退货、维修和购后支持
- 产品使用 - 设置说明、故障排除、功能解释
- 其他问题 - 特定类别未涵盖的一般查询
- “如何在iPhone 14上设置联系人?” → 产品使用
- “我购买的产品保修期是多长?” → 售后服务
- “今天天气如何?” → 其他问题
高级配置
指令和指南
在指令字段中添加详细的分类指南,以处理边缘情况、模糊场景或特定业务规则。这有助于大型语言模型理解类别之间的细微差别。记忆集成
启用记忆以在分类输入时包含对话历史。这提高了多轮对话中的准确性,其中当前输入依赖于之前的上下文。 记忆窗口控制包含多少对话历史,在上下文感知与标记数效率和处理速度之间取得平衡。输出使用
分类器输出一个包含匹配类别标签的class_name 变量。在下游节点中使用此变量用于:
条件路由 - 基于分类结果连接不同的工作流路径
知识库选择 - 路由到每个类别的专门知识库
响应自定义 - 应用不同的响应模板或处理逻辑
分析和日志记录 - 跟踪用户查询在各类别中的分布情况