

モデルの統合
LiteLLM Proxyを使用してモデルを統合する
LiteLLM Proxyは、以下の機能を提供するプロキシサーバーとなります:
- OpenAI形式の100以上のLLM(OpenAI、Azure、Vertex、Bedrock)への呼び出し
- 予算やレート制限の設定、利用状況の追跡には仮想キーを使用します
Difyは、LiteLLM Proxyで利用可能なLLMおよびテキスト埋め込み機能モデルを統合するサポートを提供します。
クイック統合
ステップ1. LiteLLM Proxyサーバーを起動する
LiteLLMには、すべてのモデルが定義された構成が必要です。このファイルを litellm_config.yaml と呼びます。
ステップ2. LiteLLM Proxyを起動する
成功すると、プロキシは http://localhost:4000 で実行されます。
ステップ3. DifyでLiteLLM Proxyを統合する
設定 > モデルプロバイダー > OpenAI-API互換 で、以下を入力してください:
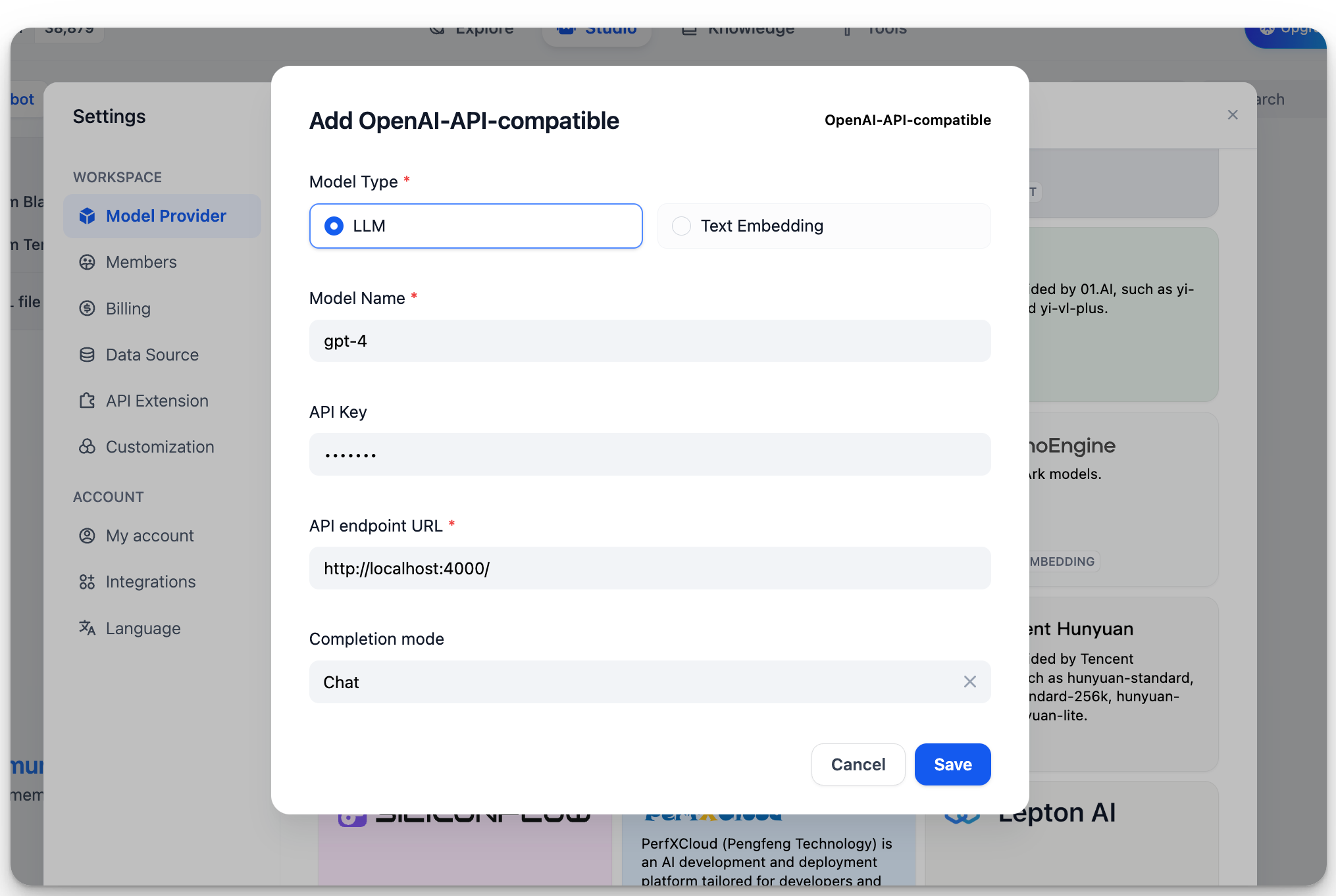
-
モデル名:
gpt-4 -
ベースURL:
http://localhost:4000LiteLLMサービスにアクセス可能なベースURLを入力します。
-
モデルタイプ:
Chat -
モデルコンテキスト長:
4096モデルの最大コンテキスト長。不明な場合は、デフォルト値の4096を使用してください。
-
トークンの最大制限:
4096モデルによって返されるトークンの最大数。モデルに特定の要件がない場合は、モデルコンテキスト長と一致させることができます。
-
ビジョンのサポート:
Yesgpt4-oのように画像理解(マルチモーダル)をサポートする場合は、このオプションをチェックしてください。
エラーがないことを確認したら、「保存」をクリックしてアプリケーションでモデルを使用してください。
埋め込みモデルの統合方法はLLMと同様で、モデルタイプをテキスト埋め込みに変更するだけです。
詳細情報
LiteLLMに関する詳細情報は、以下を参照してください: