

⚠️ このドキュメントは AI によって自動翻訳されています。不正確な部分がある場合は、英語版 を参照してください。
設定
プロンプトの作成
プロンプトは、モデルに何をすべきか、どのように応答すべきか、どのような制約に従うべきかを伝えます。 テキストジェネレーターは会話履歴のないシングルターンで実行されるため、プロンプトがモデルの唯一のコンテキストソースです。1 回のパスで正しい出力を生成するために必要な情報をすべて含めてください。 効果的なプロンプトを書くためのヒント:- タスクを明確に定義する: モデルが何を生成すべきかを明示します(例: 翻訳、要約、SQL 文)。
- 出力形式を指定する: 期待する構造、長さ、スタイルを記述します。
- 制約を設定する: モデルが避けるべきことや従うべきルールを伝えます。
query 変数がプロンプトに自動的に挿入されます。query の名前やタイプは変更可能です。
変数はプレースホルダーです。各変数はアプリ実行前にユーザーが入力する入力フィールドとなり、実行時にその値がプロンプトに挿入されます。たとえば:
- 短文
- 段落
- 選択
- 数値
- チェックボックス
- API ベースの変数
最大 256 文字まで入力可能です。名前、メールアドレス、タイトルなど、1 行に収まる短いテキスト入力に使用します。
ラベル名 は、エンドユーザーに各入力フィールドとして表示される名前です。
変数を使った動的プロンプトの作成
毎回プロンプトを書き直すことなく、異なるユーザーやコンテキストにアプリを適応させるには、変数を追加します。 各変数は特定の情報を事前に収集し、実行時にプロンプトに挿入します。 たとえば、SQL ジェネレーターではdatabase_type を使って出力の方言を適応させ、query でユーザーの自然言語リクエストをキャプチャできます:
AI でプロンプトを生成・改善する
何から始めればよいかわからない場合や、既存のプロンプトを改善したい場合は、生成 をクリックして LLM にドラフトを作成させましょう。 ゼロから望む内容を記述するか、current_prompt を参照して改善点を指定します。より的確な結果を得るには、理想的な出力 にサンプルを追加してください。
生成のたびにバージョンとして保存されるため、自由に実験してロールバックできます。
独自データに基づいた回答
一般的な知識ではなく独自のデータに基づいてモデルの回答を生成するには、ナレッジベースを追加し、既存の変数を Query Variable として選択します。 ユーザーがアプリを実行してそのフィールドに入力すると、その値が検索クエリとしてナレッジベースから関連コンテンツを取得します。取得されたコンテンツはコンテキストとしてプロンプトに挿入され、モデルがより情報に基づいた応答を生成できます。例: コンテンツライティングアプリでコンテンツタイプを使ってスタイルガイドを検索する
例: コンテンツライティングアプリでコンテンツタイプを使ってスタイルガイドを検索する
たとえば、ナレッジベースにブログ記事、ソーシャルメディアキャプション、商品説明など、さまざまなコンテンツタイプのスタイルガイドが含まれているとします。コンテンツライティングアプリで
content_type を Query Variable に設定します。ユーザーがコンテンツタイプを選択すると、アプリが対応するスタイルガイドを検索し、該当するライティング基準に従ったコピーを生成します。プロンプトは次のようになります:アプリレベルの検索設定
検索結果の処理方法を微調整するには、検索設定 をクリックします。検索設定にはナレッジベースレベルとアプリレベルの 2 つのレイヤーがあります。2 つの連続するフィルターと考えてください。ナレッジベース設定が結果の初期プールを決定し、アプリ設定がさらに結果をリランクまたはプールを絞り込みます。
-
リランク設定
- ウェイト設定 リランク時のセマンティック類似度とキーワードマッチングの相対的な重みです。セマンティックの重みを高くすると意味的な関連性が重視され、キーワードの重みを高くすると完全一致が重視されます。 ウェイト設定は、追加されたすべてのナレッジベースが 高品質 モードでインデックスされている場合のみ利用可能です。
-
リランクモデル
クエリとの関連性に基づいてすべての結果を再スコアリングし、並べ替えるリランクモデルです。
マルチモーダルのナレッジベースが追加されている場合は、マルチモーダルリランクモデル(Vision タグ付き)も選択してください。そうしないと、検索された画像がリランクと最終出力から除外されます。
- Top K リランク後に返す上位結果の最大数です。 リランクモデルが選択されている場合、この値はモデルの最大入力容量(モデルが一度に処理できるテキスト量)に基づいて自動的に調整されます。
- スコアしきい値 返される結果の最小類似度スコアです。このしきい値を下回る結果は除外されます。厳密な関連性にはより高いしきい値を、より広範なマッチングにはより低いしきい値を使用してください。
特定ドキュメント内の検索
デフォルトでは、検索はナレッジベース全体を対象とします。検索を特定のドキュメントに制限するには、手動または自動のメタデータフィルタリングを有効にします。 これにより検索精度が向上します。特にナレッジベースが大規模な場合や、異なるコンテキストのコンテンツが含まれている場合に有効です。 ドキュメントメタデータの作成と管理については、メタデータを参照してください。マルチモーダル入力の処理
エンドユーザーがファイルをアップロードできるようにするには、対応するマルチモーダル機能を持つモデルを選択します。モデルがサポートしている場合、関連するファイルタイプのトグル(ビジョン、音声、ドキュメント)が表示され、必要に応じて有効にできます。モデルのサポートするモダリティはタグで簡単に確認できます。
-
解像度: 画像 処理のみの詳細レベルを制御します。
- 高: 複雑な画像ではより高い精度が得られますが、より多くの token を使用します
- 低: シンプルな画像では、より少ない token で高速に処理します
- アップロード方法: ユーザーがデバイスからアップロード、URL の貼り付け、またはその両方を選択できます。
- アップロード制限: ユーザーが 1 回の実行あたりにアップロードできるファイルの最大数です。
セルフホスト環境では、以下の環境変数でファイルサイズの上限を調整できます:
UPLOAD_IMAGE_FILE_SIZE_LIMIT(デフォルト: 10 MB)UPLOAD_FILE_SIZE_LIMIT(デフォルト: 15 MB)UPLOAD_AUDIO_FILE_SIZE_LIMIT(デフォルト: 50 MB)
デバッグとプレビュー
右側のプレビューパネルで、アプリをリアルタイムにテストできます。タスクに最適なモデルを選択し、入力フィールドに入力して 実行 をクリックすると、出力を確認できます。 モデルを選択した後、パラメータを調整して応答の生成方法を制御できます。利用可能なパラメータとプリセットはモデルによって異なります。異なるモデル間で出力を比較するには、複数モデルでデバッグ をクリックして最大 4 つのモデルを同時に実行できます。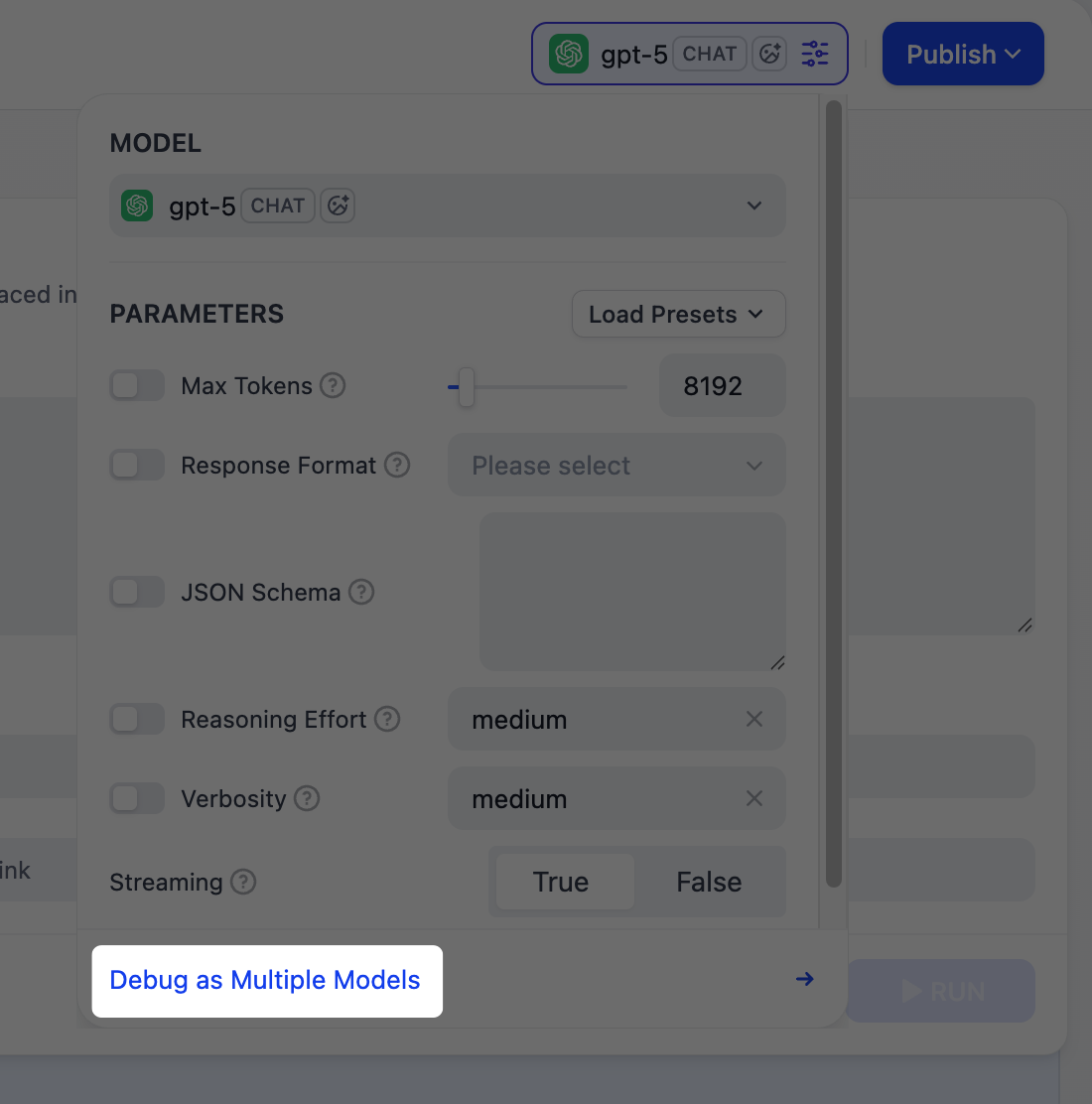
公開する
結果に満足したら、公開する をクリックしてアプリを公開します。公開オプションの全一覧は公開するを参照してください。 WebApp を実行すると、エンドユーザーは個々の出力を保存して後から参照できます。