

⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、英語版を参照してください。
ワークフローアプリ
ワークフローアプリでのFeatures経由でのファイルアップロードは廃止されました。代わりにStartノードのファイル変数を使用してください。
設定方法:
- FeaturesでImage Uploadを有効にする
- ビジョン機能付きのLLMノードを追加する
- VISIONを有効にして
sys.files変数を選択する - Endノードに接続する
チャットフローアプリ
チャットフローアプリではより多くの機能が利用できます:- Conversation Opener - AIが最初に挨拶する
- Follow-up - 応答後に次の質問を提案する
- テキスト音声変換 - 応答を音声で読み上げる(Model ProvidersでのTTSセットアップが必要)
- File Upload - ユーザーがファイルをアップロードできる
- 引用と帰属 - 知識検索を使用する際にソースを表示する
- Content Moderation - 不適切なコンテンツをフィルタリングする
ファイルアップロード
ほとんどの機能は有効にすれば自動的に動作します。ファイルアップロードはより多くの設定が必要です。 ユーザー向け:クリップアイコンをクリックしてファイルをアップロードします 開発者向け:ファイルは
開発者向け:ファイルはsys.files変数に表示されます。異なるファイルタイプには異なる処理が必要です:
ドキュメント
大規模言語モデルはファイルを直接読み取ることができません。最初にDocument Extractorを使用してください。- ファイルタイプで「Documents」を有効にする
sys.filesを入力としてDocument Extractorノードを追加する- ドキュメント抽出器の出力を使用してLLMノードを追加する
- LLMの出力でAnswerノードを追加する
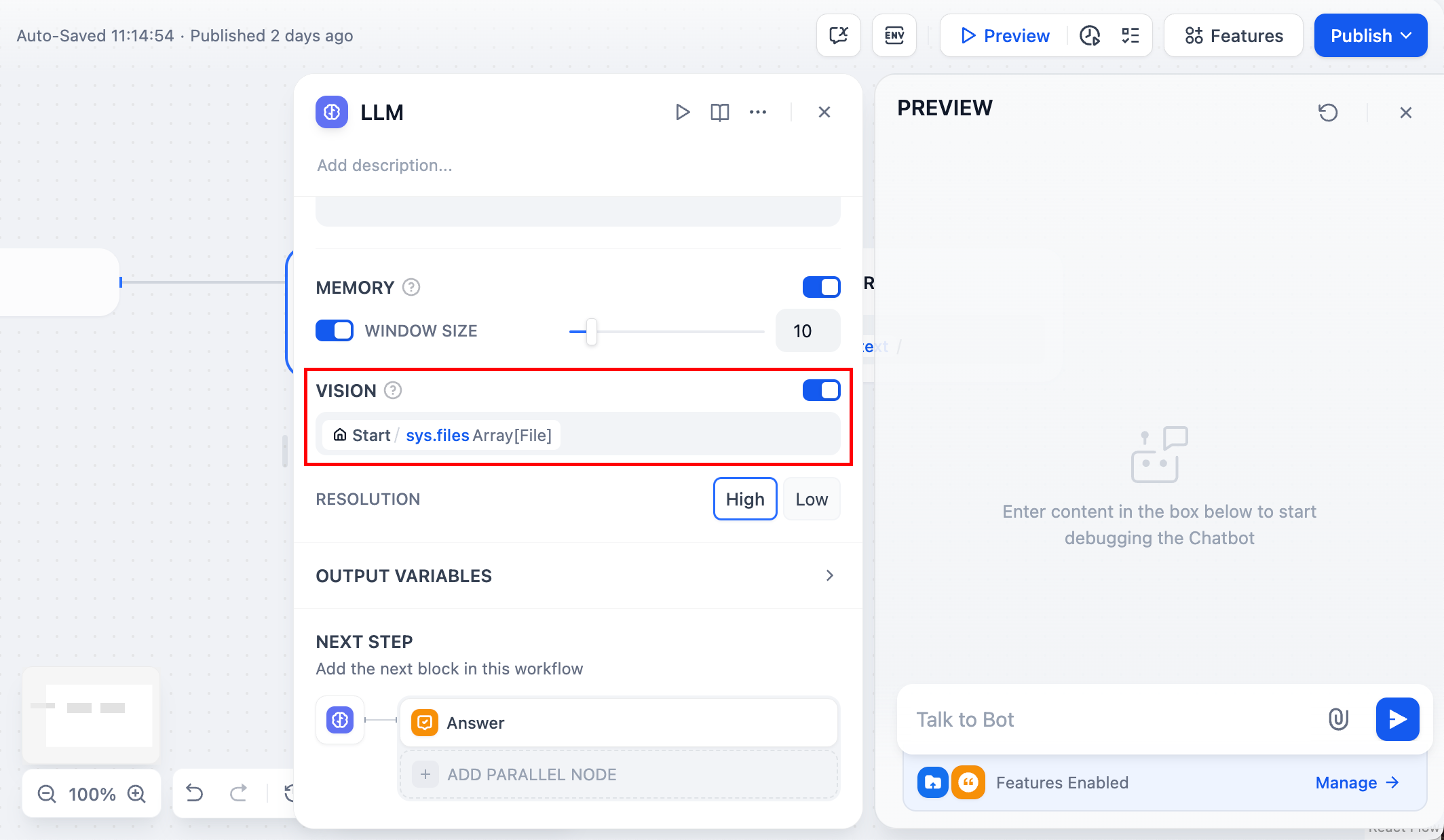
画像
一部の大規模言語モデルは画像を直接分析できます。- ファイルタイプで「Images」を有効にする
- VISIONを有効にしてLLMノードを追加する
sys.files変数を選択する- LLMの出力でAnswerノードを追加する
 .
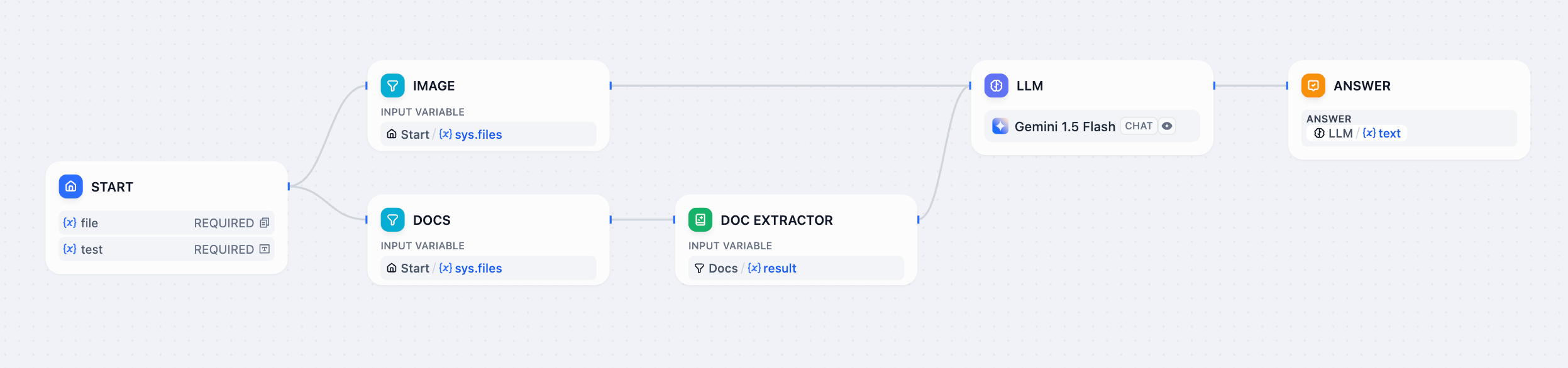
ドキュメントと画像の両方を処理する:
.
ドキュメントと画像の両方を処理する:
- 「Images」と「Documents」の両方を有効にする
- ファイルタイプをフィルタリングするために2つのList Operationノードを追加する
- 画像をビジョン機能付きLLMに送信する
- ドキュメントをDocument Extractorに送信する
- Answerノードで結果を結合する
オーディオとビデオ
大規模言語モデルはこれらを直接処理できません。オーディオ/ビデオ処理には外部ツールが必要です。制限
- ファイル1つあたり最大15MB
- 一度に最大10ファイル