

⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、英語版を参照してください。
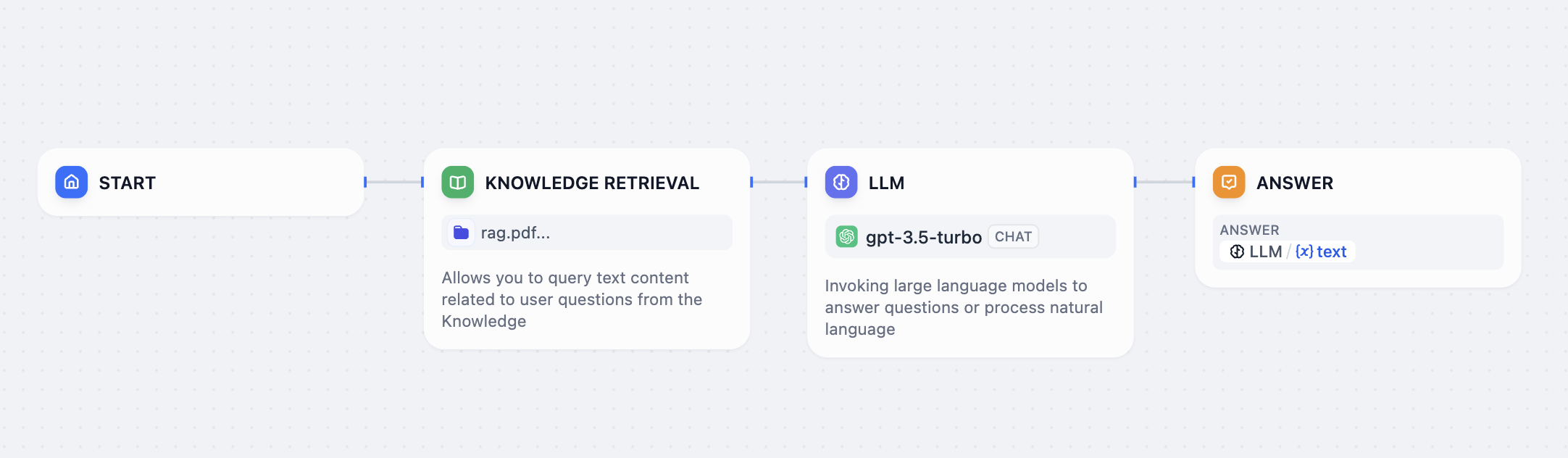
知識検索ノードの設定
このノードを使用する前に知識ベースを作成し、データを投入してください。設定手順については知識ベース作成ガイドを参照してください。
設定
クエリと知識ベースの選択
クエリは知識ベースで検索する内容を決定します。チャットフローアプリケーションでのユーザー入力にはsys.queryを使用するか、ワークフローからの任意のテキスト変数を使用してください。クエリは200文字に制限されています。
検索する知識ベースを1つ以上選択してください。それぞれにはDifyにアップロードしたインデックス化された文書が含まれています。複数の知識ベースを異なる戦略を使用して同時に検索できます。
検索戦略
コンテンツを検索する方法を選択してください:- セマンティック検索
- キーワード検索
- ハイブリッド検索
ベクトル埋め込みを使用して、意味に基づいて概念的に類似するコンテンツを見つけます。自然言語クエリや異なる用語を持つ関連概念に適しています。
高度な設定
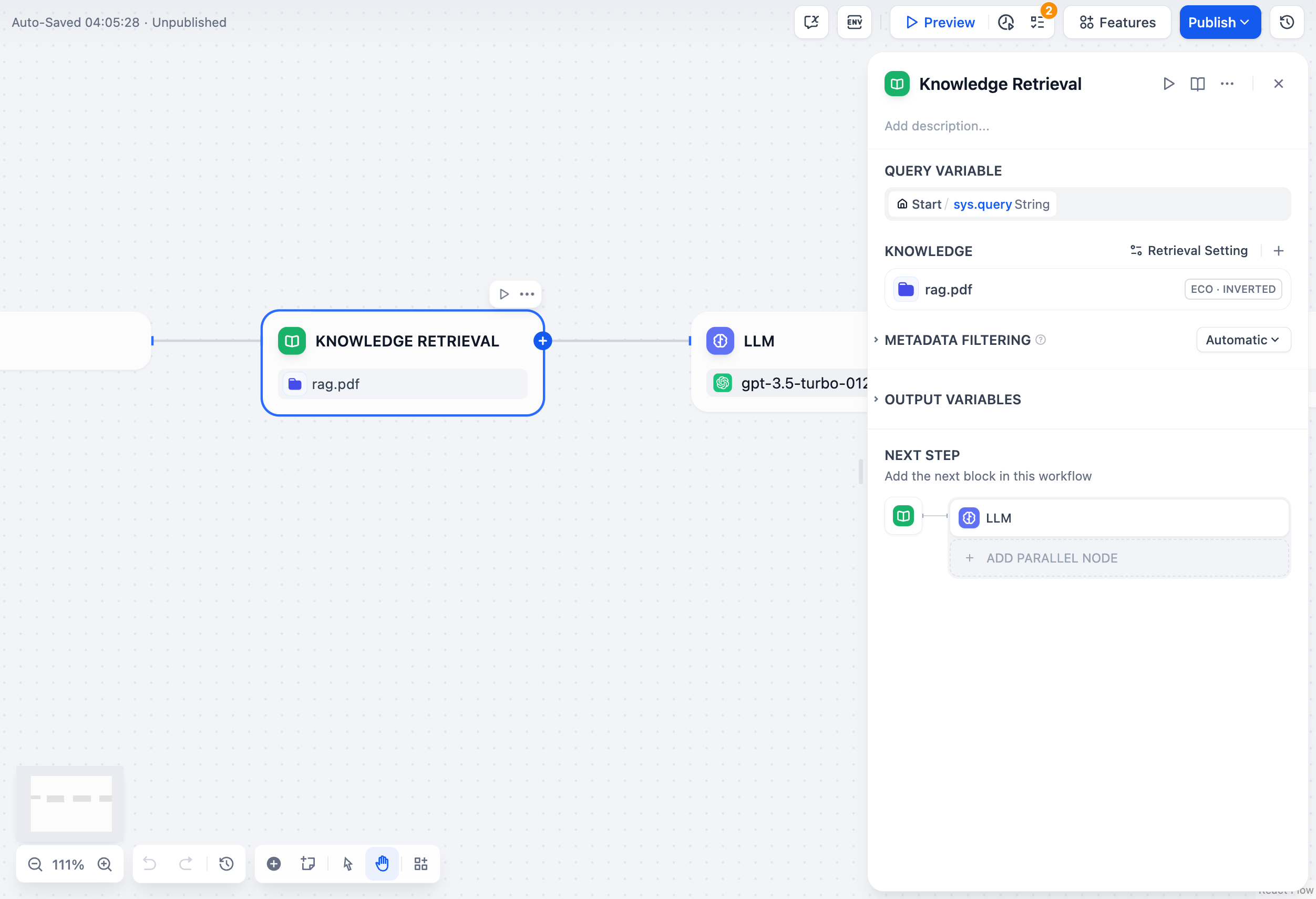
高度な検索設定オプション
検索パラメータ
TopKは取得する文書チャンクの数を制御します。集中的な結果には3-5チャンクから始めるか、包括的なカバレッジには10-15チャンクを使用してください。 スコア閾値は最小類似性スコアを設定します。高い閾値(0.7+)は関連性を保証し、低い閾値(0.5-)はより周辺的なコンテンツを含みます。 再ランキングは初期検索後に結果を再スコア化します。ハイブリッド検索、多くのチャンク、または速度よりも精度が重要な場合に有効にしてください。メタデータフィルタリング
タイプ、日付、部門などの文書メタデータを使用して結果をフィルタリングします。大きな知識ベースでのターゲット検索を可能にするために、文書をアップロードする際にメタデータを設定してください。複数知識ベース戦略
N-to-1 Recallは関数呼び出しを使用してクエリを分析し、適切な知識ベースを選択し、検索を最適化します。異最適です。 マルチパス検索は選択されたすべての知識ベースを同時にクエリし、結果を組み合わせます。情報が複数のソースにまたがる場合や包括的なカバレッジが必要な場合に使用してください。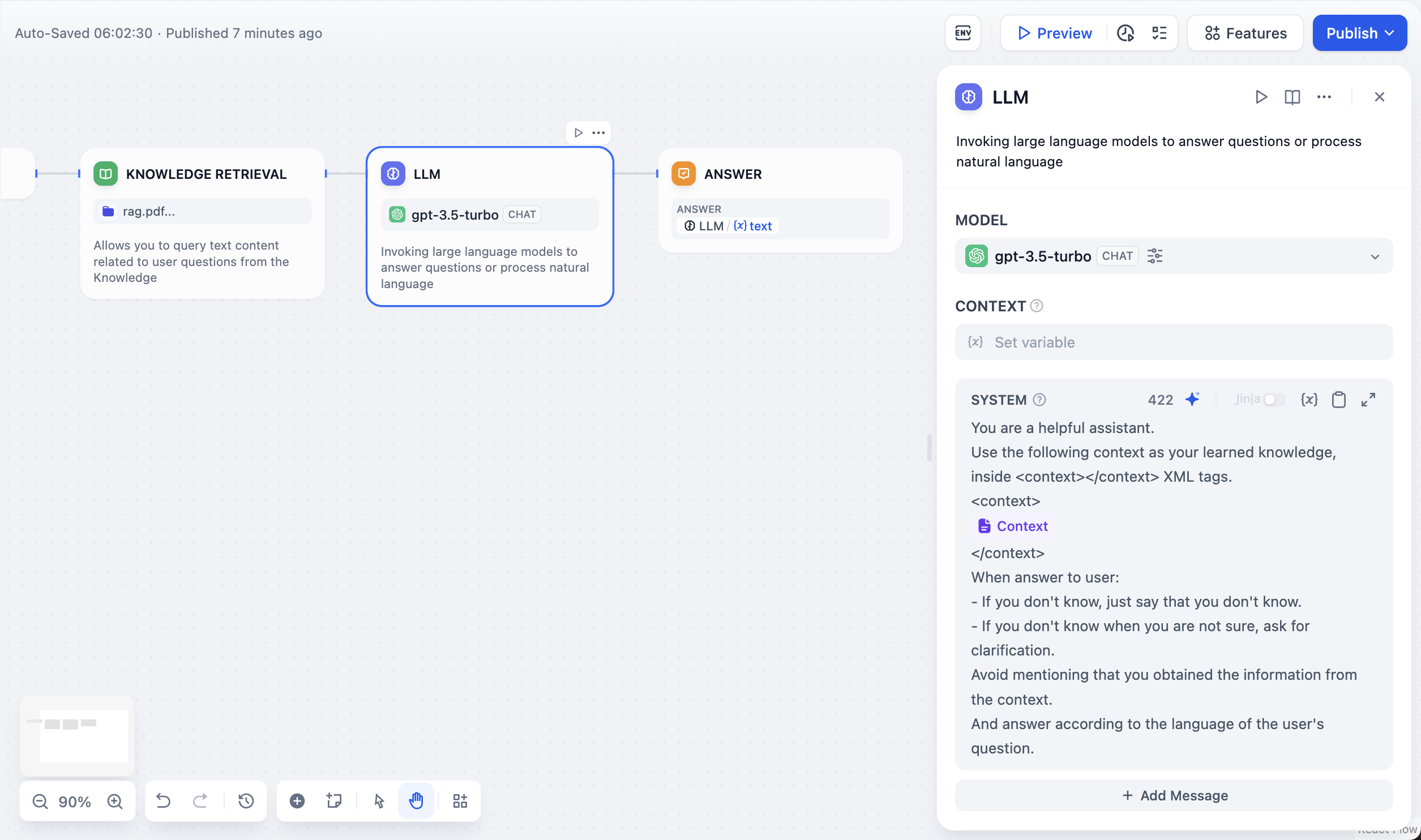
複数知識ベースの検索戦略の比較
出力と統合
このノードは、テキストコンテンツとメタデータ(ソース、スコア、文書ID)を含む取得された文書チャンクの配列を出力します。この構造化された出力は引用に必要な情報を保持します。RAG統合
RAGアプリケーション用に知識検索出力をLLMノードのコンテキスト入力に接続してください。検索結果をコンテキスト変数として使用する場合、Difyは自動的にソースを追跡し、引用を有効にします。レート制限
知識検索操作は、サブスクリプションプランに基づいてレート制限の対象となります。システムは60秒のスライディングウィンドウでRedisを使用してリクエストを追跡します。制限を超えると、RateLimitExceededエラーが返されます。