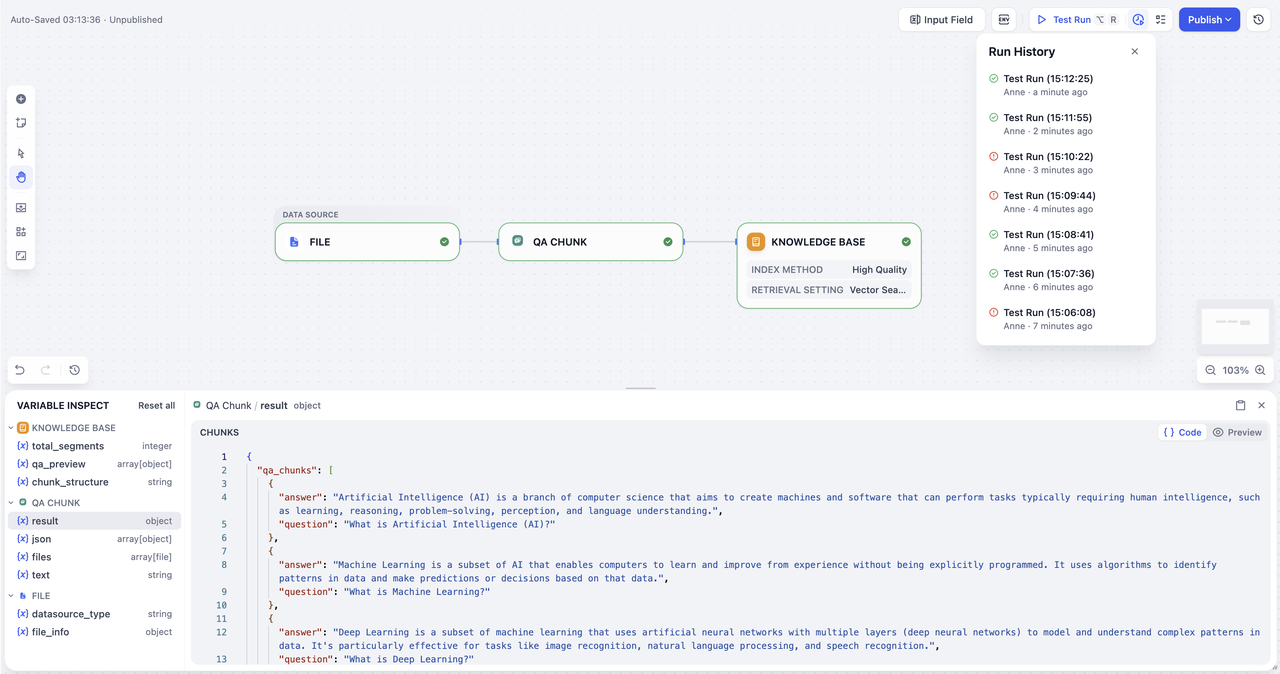
界面状态
进入知识流水线编排界面时,你会看到:- 标签页状态:Documents(文档)、Retrieval Test(召回测试)和 Settings(设置)标签页将显示为置灰且不可用状态
- 必要步骤:你必须完成知识流水线的配置、调试和发布后,才能上传文件或使用其他功能
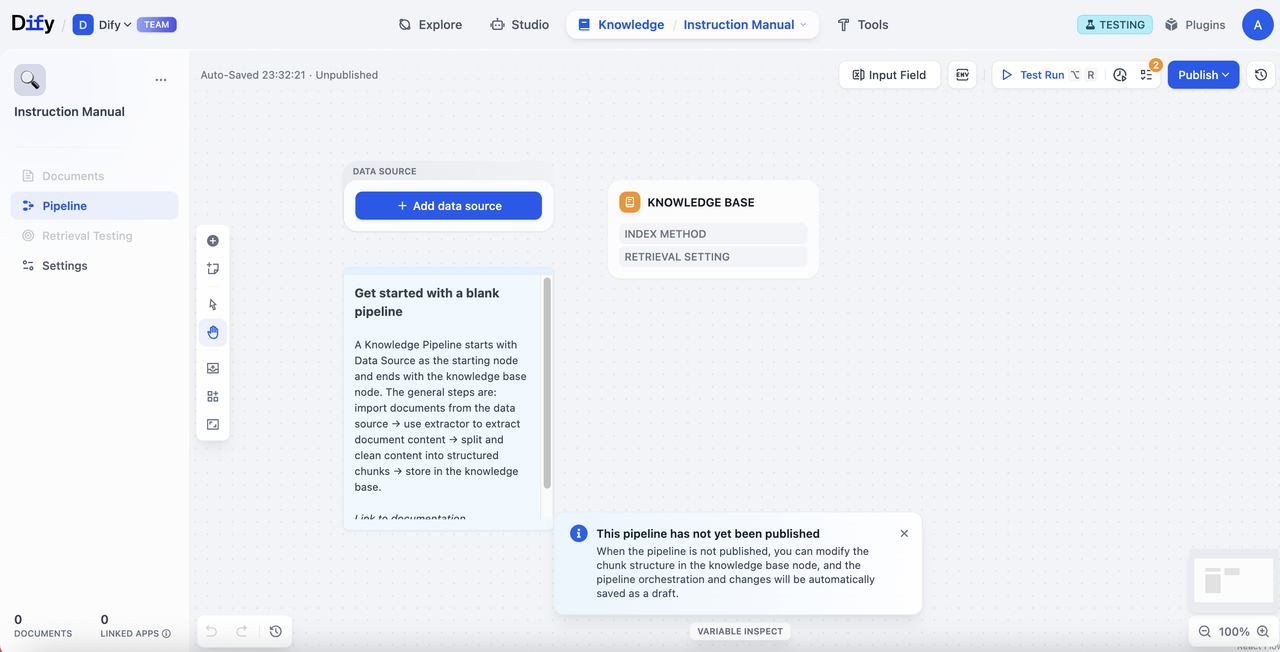
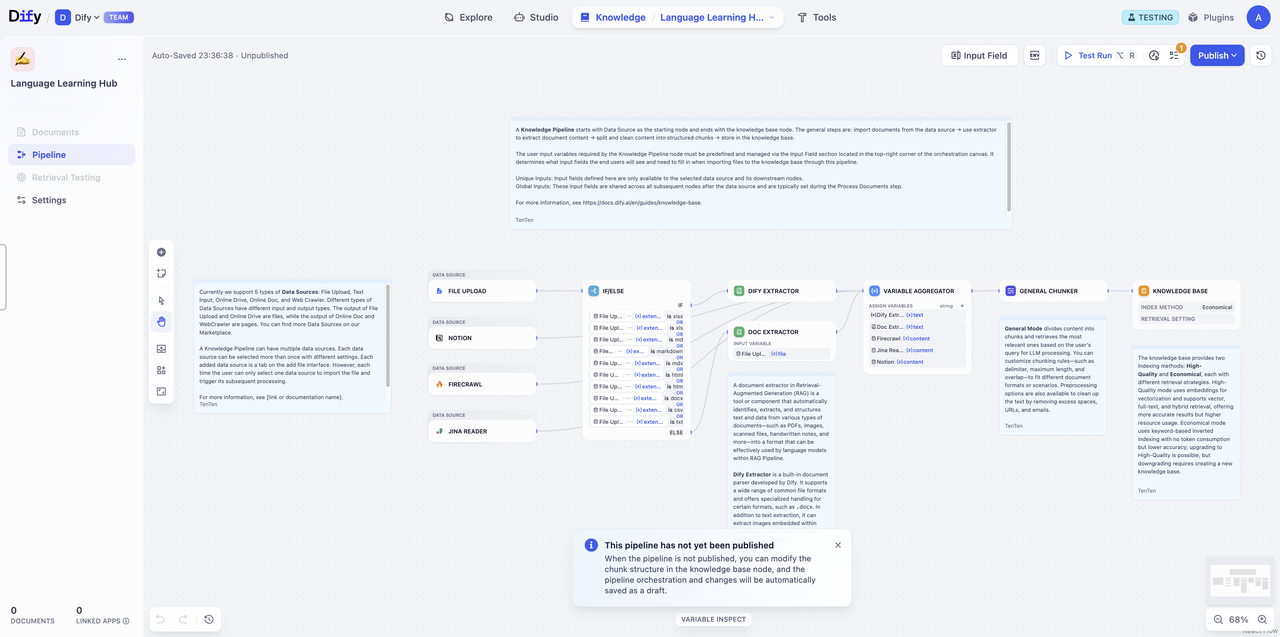
知识流水线处理流程
在开始之前,我们先拆解知识流水线的处理流程,你可以更好地理解数据是如何一步步转化为可用的知识库。- 数据源配置:来自各种数据源的原始内容(本地文件、Notion、网页等)
- 数据处理节点配置:处理和转换数据内容
- 提取器 (Extractor) → 解析和结构化原始文档内容
- 分块器 (Chunker) → 将结构化内容分割为适合处理的片段
- 知识库节点配置:设置知识库的分段结构和检索策略
- 用户输入表单配置:定义流水线使用者需要输入的参数
- 测试与发布:验证并正式启用知识库
步骤一:数据源配置
在一个知识库里,你可以选择单一或多个数据源。每个数据源可以被多次选中,并包含不同配置。目前,Dify 支持 4 种数据源:文件上传、在线网盘、在线文档和网页爬虫。 你也可以前往 Dify Marketplace,获得更多数据源。文件上传
用户可以直接选择本地文件进行上传,以下是配置选项和限制。
配置选择
限制
输出变量
| 配置项 | 说明 |
|---|---|
| 文件格式 | 支持 pdf, xlxs, docs 等,用户可自定义选择 |
| 上传方式 | 通过拖拽或选择文件或文件夹上传本地文件,支持批量上传 |
| 限制项 | 说明 |
|---|---|
| 文件数量 | 每次最多上传 50 个文件 |
| 文件大小 | 每个文件大小不超过 15MB |
| 储存限制 | 不同 SaaS 版本的订阅计划对文档上传总数和向量存储空间有所限制 |
| 输出变量 | 变量格式 |
|---|---|
{x} Document | 单个文档 |
在线文档
Notion
将知识库连接 Notion 工作区,可直接导入 Notion 页面和数据库内容,支持后续的数据自动同步。
配置选项说明
| 配置项 | 选项 | 输出变量 | 说明 |
|---|---|---|---|
| Extractor | 开启 | {x} Content | 输出结构化处理的页面信息 |
| 关闭 | {x} Document | 输出页面的原始文本信息 |
网页爬虫
将网页内容转化为大型语言模型容易识别的格式,知识库支持 Jina Reader 和 Firecrawl,提供灵活的网页解析能力。Jina Reader
开源网页解析工具,提供简洁易用的 API 服务,适合快速抓取和处理网页内容。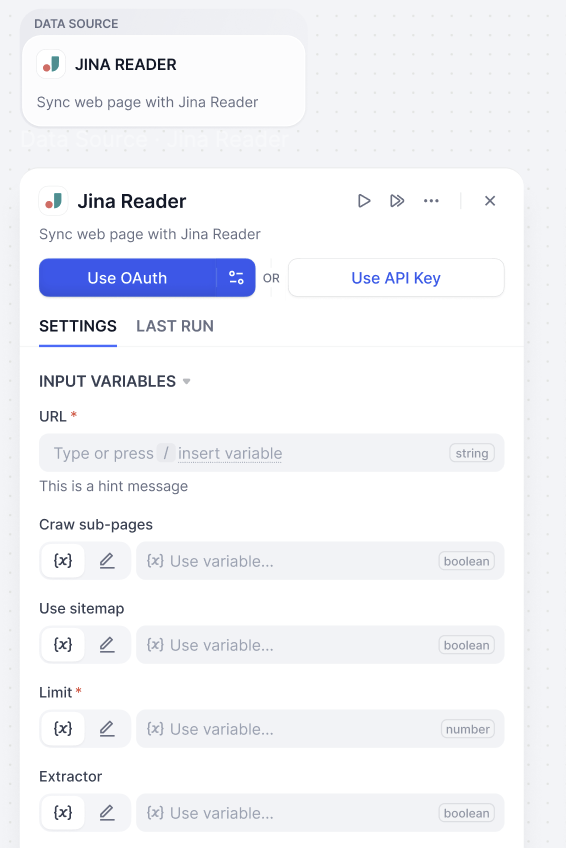
参数配置和说明
| 参数 | 类型 | 说明 |
|---|---|---|
| URL | 必填 | 目标网页地址 |
| 爬取子页面 (Crawl sub-page) | 可选 | 是否抓取链接页面 |
| 使用站点地图 (Use sitemap) | 可选 | 利用网站地图进行爬取 |
| 爬取页数限制 (Limit) | 必填 | 设置最大抓取页面数量 |
| 启用内容提取器 (Enable Extractor) | 可选 | 选择数据提取方式 |
Firecrawl
开源网页解析工具,提供更精细的爬取控制选项和 API 服务,支持复杂网站结构的深度爬取,适合需要批量处理和精确控制的场景。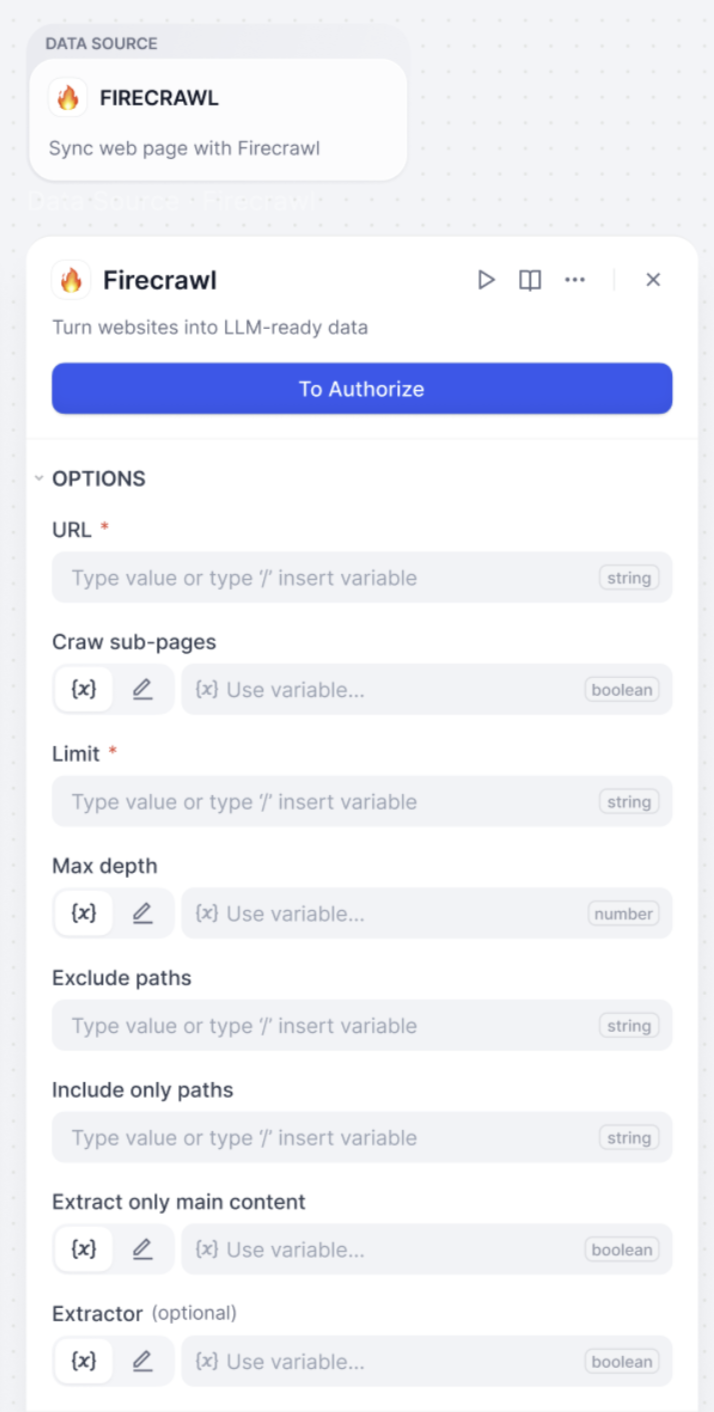
参数配置和说明
| 参数 | 类型 | 说明 |
|---|---|---|
| URL | 必填 | 目标网页地址 |
| 爬取页数限制 (Limit) | 必填 | 设置最大抓取页面数量 |
| 爬取子页面 (Crawl sub-page) | 可选 | 是否抓取链接页面 |
| 最大爬取深度 (Max depth) | 可选 | 控制爬取层级深度 |
| 排除路径 (Exclude paths) | 可选 | 设置不爬取的页面路径 |
| 仅包含路径 (Include only paths) | 可选 | 限制只爬取指定路径 |
| 启用内容提取器 (Enable Extractor) | 可选 | 选择数据处理方式 |
| 只提取主要内容 | 可选 | 过滤页面辅助信息 |
在线网盘
连接你的在线云储存服务(例如 Google Drive、Dropbox、OneDrive),Dify 将自动检索云储存中的文件,你可以勾选并导入相应文档进行下一步处理,无需手动下载文件再进行上传。步骤二:配置数据处理节点
该阶段是内容的预处理与数据结构化过程,这一部分将会把数据源进行提取、分段并转换为适合知识库存储和检索的格式。你可以将这一步想象成备餐过程——处理原材料、进行清理、切分成小块,并整理好一切,以便在有人需要时能迅速”烹制”出这道”菜肴”。文档处理
由于知识库无法直接理解 PDF、Word 等各种文档格式,提取器负责将这些文档”解读”成系统可以处理的文本内容。它支持多种常见文件格式,确保你的文档内容能够被正确提取和处理,并转换为大型语言模型可以有效使用的格式。 你可以选择 Dify 文档提取器来处理文件,也可以根据你的需求从 Dify Marketplace 中选择更多工具。Marketplace 提供了如 Dify Extractor、Unstructured 等第三方工具。文档提取器 (Doc Extractor)

Dify 提取器 (Dify Extractor)
Dify Extractor 是 Dify 开发的一款内置文档解析器。它支持多种常见文件格式,并针对 Doc 文件进行了专门优化。它能够从文档中提取图片,进行存储并返回图片的 URL。
Unstructured
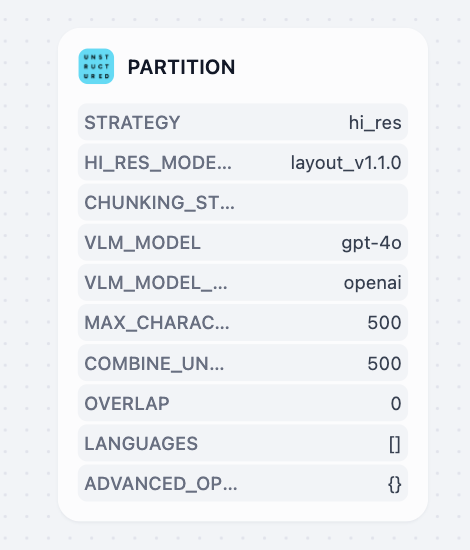
Unstructured 将文档转换为结构化的机器可读格式,具有高度可定制的处理策略。它提供多种提取策略(auto、hi_res、fast、OCR-only)和分块方法(by_title、by_page、by_similarity)来处理各种文档类型,提供详细的元素级元数据,包括坐标、置信度分数和布局信息。推荐用于企业文档工作流、混合文件类型处理以及需要精确控制文档处理参数的场景。
分块器 (Chunker)
在构建 AI 应用时,我们需要处理大量和不同种类的文档内容,比如产品手册、技术文档或论文等。和人类有限的注意力相似,大型语言模型无法同时处理过多的信息。因此,在信息提取后,分块器将大段的文档内容拆分成更小、更易于管理的片段(称为”块”)。这就好比一本很厚的书,被分成了许多章节,你可以通过阅读目录快速定位到相关内容所在章节。 当 AI 应用需要回答问题时,良好的分块策略能够提供足够的上下文信息,并包含完整的语义。这样,当检索到对应的片段时,大型语言模型能够基于这个片段中的信息生成较为准确的答案。 不同类型的文档需要不同的分块策略,比如产品手册可能需要按照产品型号进行分块,确保产品功能介绍的完整性;论文则需要根据逻辑结构进行分块,确保论点叙述的流畅性。基于这样的多样性,Dify 提供了 3 种分块器,帮助你根据不同文档类型和使用场景进行选择和使用。分块器类型概述
| 类型 | 特点 | 使用场景 |
|---|---|---|
| 通用分块器 | 固定大小分块,支持自定义分隔符 | 结构简单的基础文档 |
| 父子分块器 | 双层分段结构,平衡匹配精准度和上下文 | 需要较多上下文信息的复杂文档结构 |
| 问答处理器 | 处理表格中的问答组合 | CSV 和 Excel 的结构化问答数据 |
通用文本预处理规则
| 处理选项 | 说明 |
|---|---|
| 替换连续空格、换行符和制表符 | 将文档中的连续空格、换行符和制表符替换为单个空格 |
| 移除所有 URL 和邮箱地址 | 自动识别并移除文本中的网址链接和邮箱地址 |
通用分块器 (General Chunker)
基础文档分块处理,适用于结构相对简单的文档,你可以参考下面的配置对文本的分块、文本预处理规则进行配置。 输入输出变量| 类型 | 变量 | 说明 |
|---|---|---|
| 输入变量 | {x} Content | 完整的文档内容块,通用分块器将其拆分为若干小段 |
| 输出变量 | {x} Array[Chunk] | 分块后的内容数组,每个片段适合进行检索和分析 |
| 配置项 | 说明 |
|---|---|
| 分段标识符 (Delimiter) | 默认值为 \n,即按照文本段落分段。你可以遵循正则表达式语法自定义分块规则,系统将在文本出现分段标识符时自动执行分段。 |
| 分段最大长度 (Maximum Chunk Length) | 指定分段内的文本字符数最大上限,超出该长度时将强制分段。 |
| 分段重叠长度 (Chunk Overlap) | 对数据进行分段时,段与段之间存在一定的重叠部分。这种重叠可以帮助提高信息的保留和分析的准确性,提升召回效果。 |
父子分块器 (Parent-child Chunker)
父子分块器采用双层分段结构解决了上下文与准确度之间的矛盾,在检索增强生成(RAG)系统中实现了准确匹配与全面的上下文信息的平衡。 父子检索的工作机制- 使用子分块匹配查询:使用小而精准的信息片段(通常简洁到段落中的单个句子)来匹配用户查询。这些子分块能够实现精确且相关的初始检索。
- 父分块提供丰富的上下文:检索包含匹配子分块的更大范围内容(如段落、章节甚至整个文档)。这些父分块为大语言模型(LLM)提供全面的上下文信息。
| 类型 | 变量 | 说明 |
|---|---|---|
| 输入变量 | {x} Content | 完整的文档内容块,通用分块器将其拆分为若干小段 |
| 输出变量 | {x} Array[ParentChunk] | 父分块数组 |
| 配置项 | 说明 |
|---|---|
| 父分块分隔符 (Parent Delimiter) | 设置父分块的分割标识符 |
| 父分块最大长度 (Parent Maximum Chunk Length) | 控制父分块的最大字符数 |
| 子分块分隔符 (Child Delimiter) | 设置子分块的分割标识符 |
| 子分块最大长度 (Child Maximum Chunk Length) | 控制子分块的最大字符数 |
| 父块模式 (Parent Mode) | 选择”段落”(将文本分割为段落)或”完整文档”(使用整个文档作为父分块)进行直接检索 |
问答处理器 Q&A Processor (Extractor+Chunker)
问答处理器结合了提取和分块功能,专门用于处理 CSV 和 Excel 文件的结构化问答数据集,比如常见问题(FAQ)列表、排班表等。 输入输出变量| 类型 | 变量 | 说明 |
|---|---|---|
| 输入变量 | {x} Document | 单个文档 |
| 输出变量 | {x} Array[QAChunk] | 问答分块数组 |
| 名称 | 说明 |
|---|---|
| 问题所在的列 | 将内容所在的列设置为问题 |
| 答案所在的列 | 将内容所在的列设置为答案 |
步骤三:配置知识库节点
在完成数据处理后,我们将进入知识流水线的最后一个环节 — 知识库节点。你可以根据实际需求,在这个节点选择不同的索引方法和检索策略,以获得最适合的检索效果和成本控制。 知识库节点配置分为以下部分:输入变量、分段结构、索引方式以及检索设置。分段结构 (Chunk Structure)
通用模式
适用于大多数标准文档处理场景。 通用模式提供灵活的索引选项,你可以根据对质量和成本的不同要求选择合适的索引方法。通用模式支持高质量和经济的索引方式,以及多种检索设置。父子模式
父子模式能够在检索时,提供精确匹配和对应的上下文信息,适用于需要保持完整上下文的专业文档。父子模式仅支持 HQ (高质量)模式,检索时提供子分块匹配和父分块上下文。问答模式 (Question-Answer)
在使用结构化问答数据时,你可以创建问题与答案配对的文档。这些文档会根据问题部分进行索引,从而使系统能够根据查询相似性检索到相关的答案。问答模式仅支持 HQ(高质量)模式。输入变量 (Input Variable)
输入变量用于接收来自数据处理节点的处理结果,用作知识库构建的数据源。你需要将前面配置的分块器节点的输出,连接到知识库节点并作为输入。 该节点根据所选的分段结构,支持不同类型的标准输入:- 通用模式:
{x} Array[Chunk]- 通用分块数组 - 父子模式:
{x} Array[ParentChunk]- 父分块数组 - 问答模式:
{x} Array[QAChunk]- 问答分块数组
索引方式 (Index Method) 与检索设置 (Retrieval Setting)
索引方式决定了知识库如何建立内容索引,检索设置则基于所选的索引方式提供相应的检索策略。你可以这么理解,索引方式决定了整理文档的方式,而检索设置告知使用者可以用什么方法来查找文档。 知识库提供了两种索引方式:高质量和经济,分别提供不同的检索设置选项。 在高质量模式下,使用 Embedding 嵌入模型将已分段的文本块转换为数字向量,帮助更加有效地压缩与存储大量文本信息。这使得即使用户的问题用词与文档不完全相同,系统也能找到语义相关的准确答案。索引方式和检索设置
| 索引方式 | 可用检索设置 | 说明 |
|---|---|---|
| 高质量 | 向量搜索 | 基于语义相似度,理解查询深层含义。 |
| 全文检索 | 基于关键词匹配的检索方式,提供全面的检索能力。 | |
| 混合检索 | 结合语义和关键词 | |
| 经济 | 倒排索引 | 搜索引擎常用的检索方法,匹配问题与关键内容。 |
| 分段结构 | 可选索引方式 | 可配置参数 | 可用检索设置 |
|---|---|---|---|
| 通用模式 | 高质量 经济 | Embedding 嵌入模型 关键词数量 | 向量检索 全文检索 混合检索 倒排索引 |
| 父子模式 | 高质量(仅支持) | Embedding Model 嵌入模型 | 向量检索 全文检索 混合检索 |
| 问答模式 | 高质量(仅支持) | Embedding Model 嵌入模型 | 向量检索 全文检索 混合检索 |
步骤四:配置用户输入表单
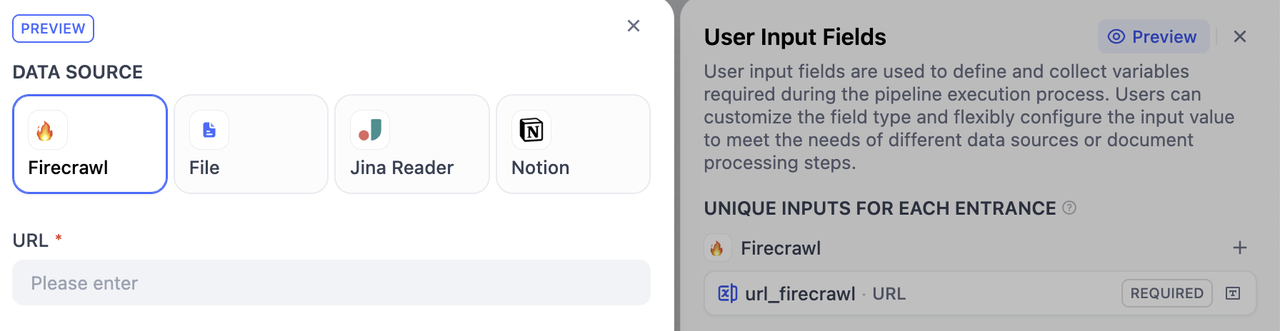
用户输入表单对于收集流水线运行所需的有效初始信息非常重要。类似于工作流中的开始节点,这个表单从用户那里收集必要的相信信息,比如:需要上传的文件、文档处理的特定参数等,确保流水线拥有提供准确结果所需要的所有信息。 通过这种方式,你可以为不同的使用场景创建特定的的输入表单,提高流水线对于不同数据源和文档处理流程的灵活性和易用性。创建用户输入表单
你可以通过下面两种方式,创建用户输入表单。-
知识流水线编排界面 点击输入字段(Input Field)开始创建和配置输入表单。

-
节点参数面板 选中节点,在右侧的面板需要填写的参数内,点击最下方的
+ 创建用户输入字段(+ Create user input)来创建新的输入项。新增的输入项将会汇总到输入字段(Input Field)的表单内。
输入类型
非共享输入 (Unique Inputs for Each Entrance)
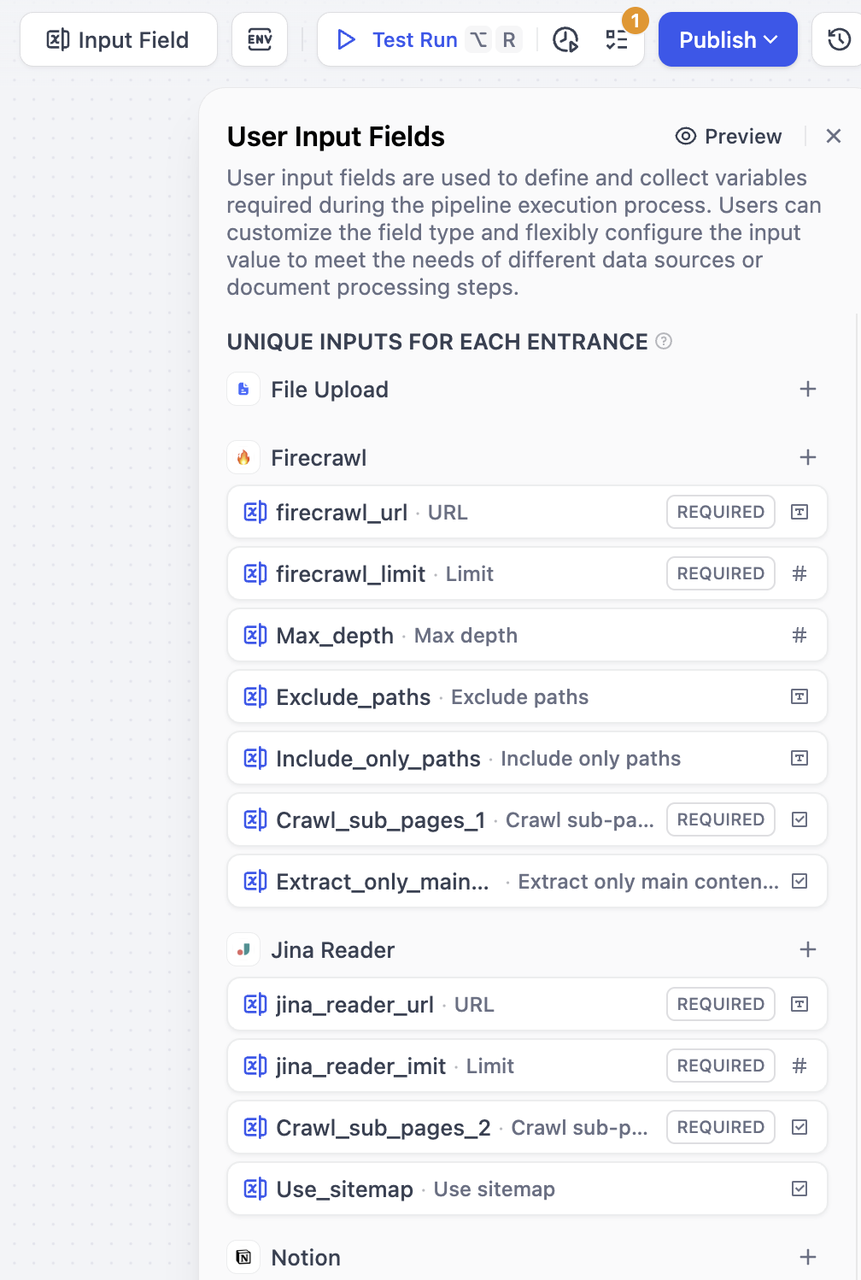
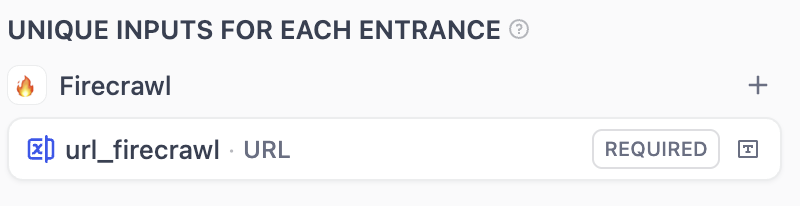
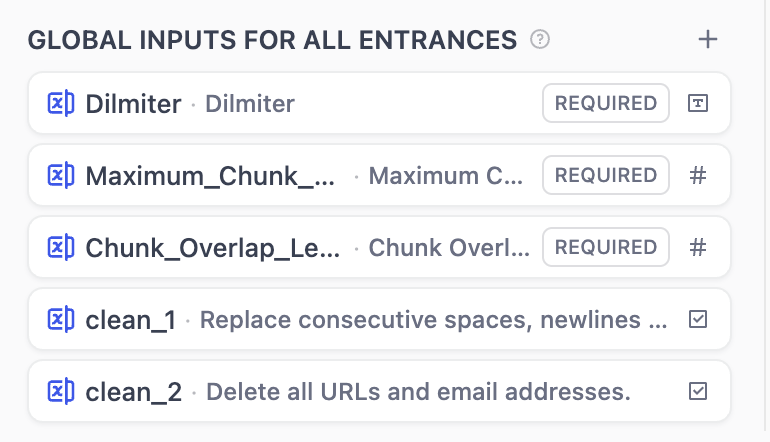
全局共享输入 (Global Inputs for All Entrance)
支持字段类型和填写说明
知识流水线支持以下七种类型的输入变量。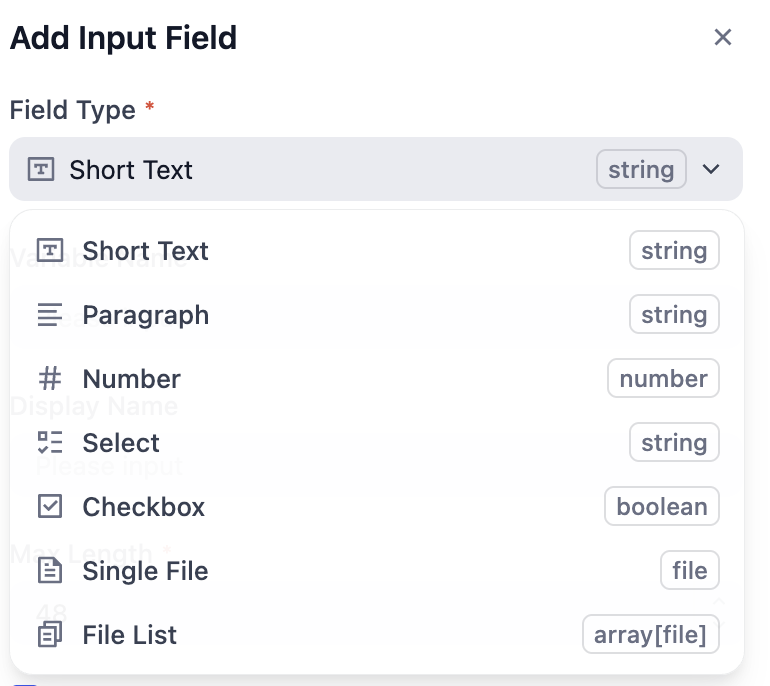
| 字段类型 | 说明 |
|---|---|
| 文本 | 短文本,由知识库使用者自行填写,最大长度为 256 字符 |
| 段落 | 长文本,知识库使用者可以输入较长字符 |
| 下拉选项 | 由编排者预设的固定选项供使用者选择,使用者无法自行填写内容 |
| 布尔值 | 只有真/假两个取值 |
| 数字 | 只能输入数字 |
| 单文件 | 上传单个文件,支持多种文件类型(文档、图片、音频、视频和其他文件类型) |
| 文件列表 | 批量上传文件,支持多种文件类型(文档、图片、音频、视频和其他文件类型) |
| 名称 | 说明 | 示例 |
|---|---|---|
| 必填项 | ||
| 变量名称 Variable Name | 系统内部标识名称,通常使用英文和下划线进行命名 | user_email |
| 显示名称 Display Name | 界面展示的名称,通常是简洁易读的文字 | 用户邮箱 |
| 类型特定设置 | 不同字段类型的特殊要求 | 文本的最大长度为 100 字符 |
| 更多设置 | ||
| 默认值 Default Value | 用户未输入时的默认值 | 数字字段默认为0, 文本字段默认为空 |
| 占位符 Placeholder | 输入框空白时的提示文字 | 请输入你的邮箱 |
| 提示 Tooltip | 解释或指引用户进行填写的文字,通常在用户鼠标悬停时显示 | 请输入有效的邮箱地址 |
| 特殊非必填信息 | 根据不同字段类型的额外设置选项 | 邮箱格式验证 |
步骤五:为知识库命名
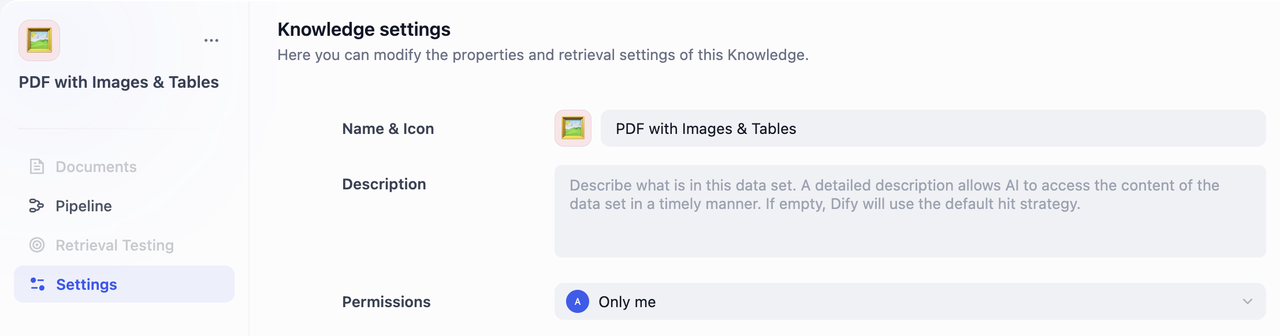
- 名称和图标 为你的知识库命名。你还可以选择一个 emoji、上传图片或粘贴图片 URL 作为知识库的图标。
- 知识库描述 简要描述你的知识库。这有助于 AI 更好地理解和检索你的数据。如果留空,Dify 将应用默认的检索策略。
- 权限 从下拉菜单中选择适当的访问权限。
步骤六:测试
在完成编排后,你需要先验证配置的完整性,然后测试流水线运行效果,确认各项设置正确无误,最后发布知识库。检查配置完成度
在进行测试前,建议先检查配置的完整性,避免因遗漏配置而导致测试失败。 点击右上角的检查清单按钮,系统会显示遗漏部分。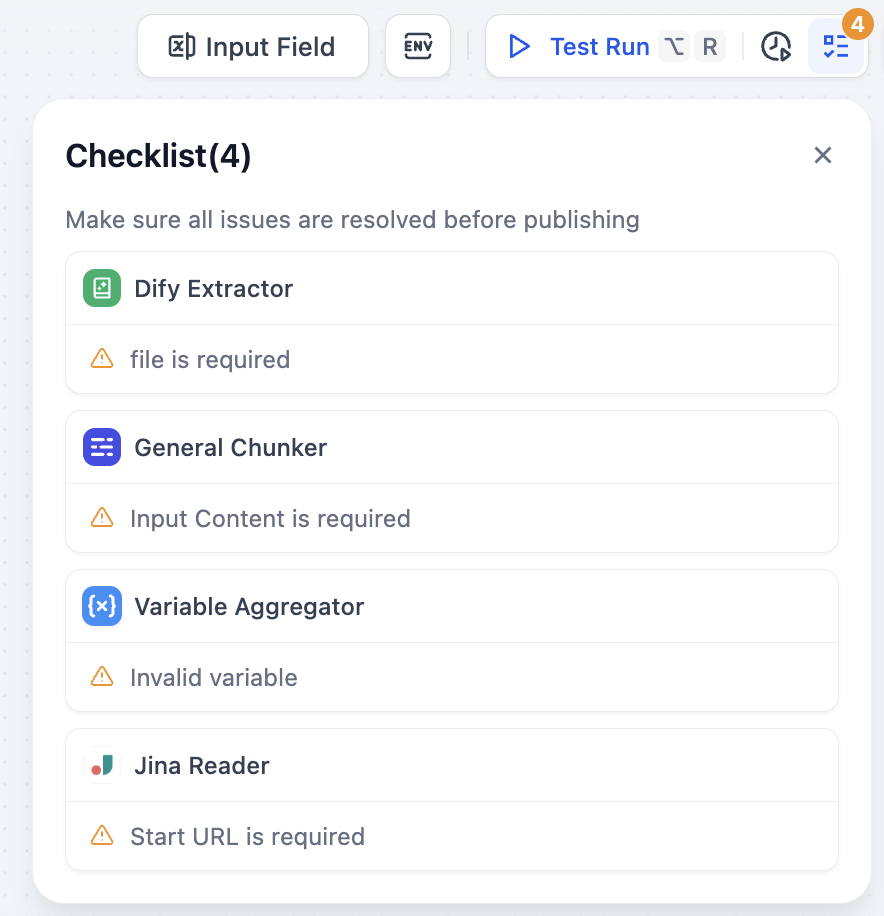
测试运行 (Test Run)

- 开始测试:点击右上角的测试运行(Test Run)按钮。
- 导入测试文件:在右侧弹出的数据源窗口中,导入文件。
- 填写参数:导入成功后,根据你之前配置的用户输入表单填写对应参数
- 开始试运行:点击下一步,开始测试整个流水线。