

LLM
定義
大規模言語モデルを活用して質問に回答したり、自然言語を処理したりします。
LLMノード
シナリオ
LLM は チャットフロー/ワークフロー の中心的なノードであり、大規模言語モデルの会話/生成/分類/処理などの能力を活用して、多様なタスクを提示されたプロンプトに基づいて処理し、ワークフローのさまざまな段階で使用することができます。
- 意図識別:カスタマーサービスの対話シナリオにおいて、ユーザーの質問を意図識別および分類し、異なるフローに誘導します。
- テキスト生成:記事生成シナリオにおいて、テーマやキーワードに基づいて適切なテキスト内容を生成するノードとして機能します。
- 内容分類:メールのバッチ処理シナリオにおいて、メールの種類を自動的に分類します(例:問い合わせ/苦情/スパム)。
- テキスト変換:テキスト翻訳シナリオにおいて、ユーザーが提供したテキスト内容を指定された言語に翻訳します。
- コード生成:プログラミング支援シナリオにおいて、ユーザーの要求に基づいて指定のビジネスコードやテストケースを生成します。
- RAG:ナレッジベースの質問応答シナリオにおいて、検索した関連知識とユーザーの質問を再構成して回答します。
- 画像理解:ビジョン能力を持つマルチモーダルモデルを使用し、画像内の情報を理解して質問に回答します。
適切なモデルを選択し、プロンプトを記述することで、チャットフロー/ワークフロー で強力で信頼性の高いソリューションを構築できます。
設定方法
エディットページで、前のノードの末尾を右クリックするか、+ボタンを軽くタップして新しいノードを追加し、LLM(大規模言語モデル)を選択します。
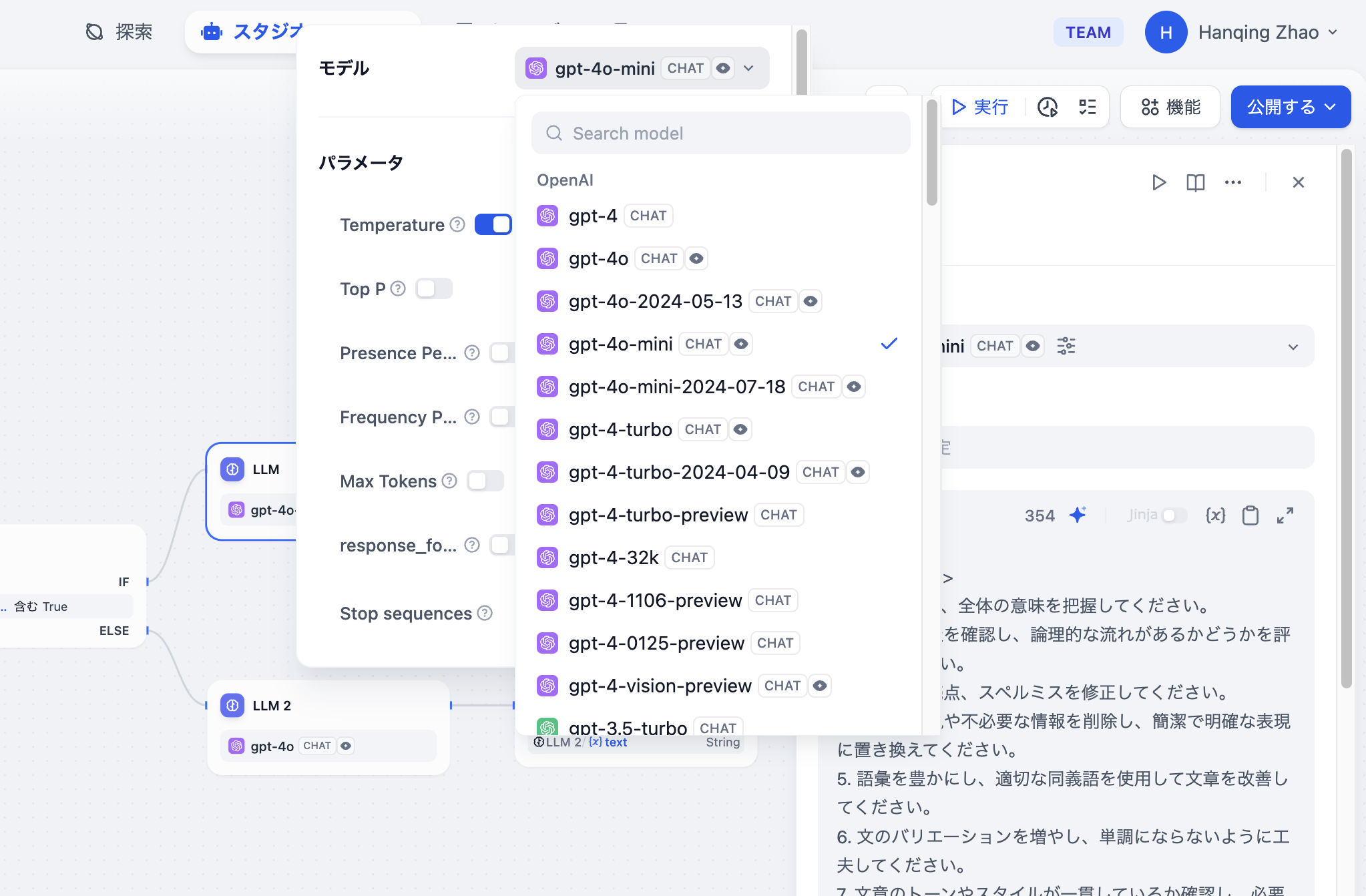
LLM ノード設定 - モデル選択
設定手順:
- モデルの選択:Difyでは、OpenAIのGPTシリーズ、AnthropicのClaudeシリーズ、GoogleのGeminiシリーズなど、世界中で広く使用されているさまざまなモデルをサポートしています。モデルの選択は、推論能力、コスト、応答速度、コンテキストウィンドウのサイズなどの要因に基づいて行います。使用するシーンやタスクの種類に応じて、適切なモデルを選ぶことが重要です。
Difyを初めて使用する場合は、LLMノードでモデルを選択する前に、システム設定 - モデルプロバイダでモデルの設定を事前に行う必要があります。
- モデルパラメータの設定:モデルパラメータは、生成される結果を調整するために使用されます。これには、温度、TopP、最大トークン数、応答形式などが含まれます。選択肢を簡素化するために、3つの事前設定されたパラメータ(クリエイティブ、バランス、精密)が用意されています。これらのパラメータに不慣れな場合は、デフォルト設定を選択することをお勧めします。画像解析機能を利用したい場合は、視覚能力を持つモデルを選んでください。
- コンテキストの入力(オプション):コンテキストとは、LLMに提供される背景情報のことを指します。通常は、知識検索の出力変数を記入するために使用されます。
- プロンプトの作成:LLMノードには使いやすいプロンプト編集ページがあり、チャットモデルまたはコンプリートモデルを選択することで異なるプロンプト編集構造が表示されます。チャットモデル(Chat model)を選択した場合、システムプロンプト(SYSTEM)、ユーザー(USER)、アシスタント(ASSISTANT)の3つのセクションをカスタマイズできます。
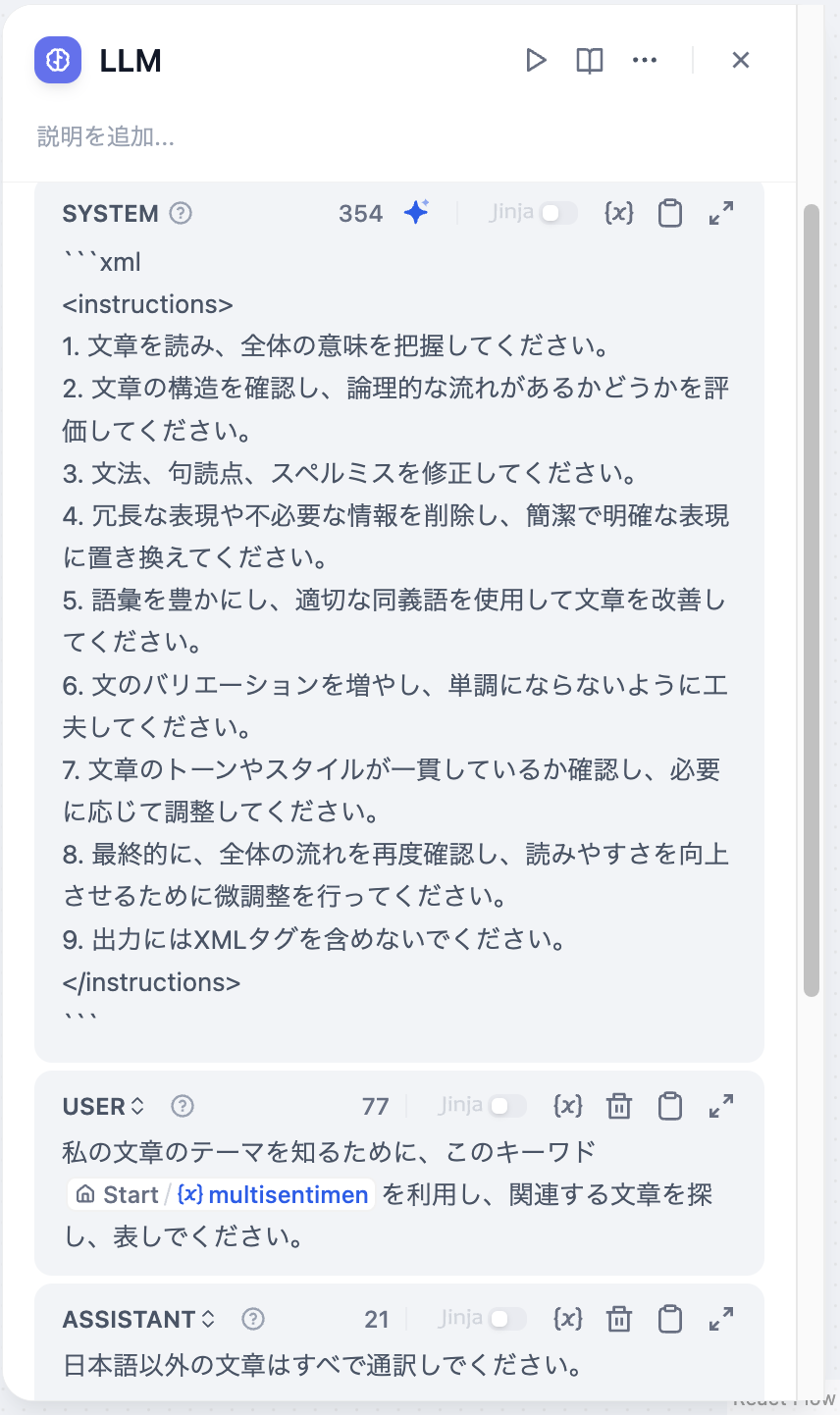
プロンプトの作成
システムプロンプト(SYSTEM)を作成する際にアイデアが浮かばない場合は、プロンプトジェネレーター機能を使用して、実際のビジネスシナリオに適したプロンプトを迅速に生成することができます。
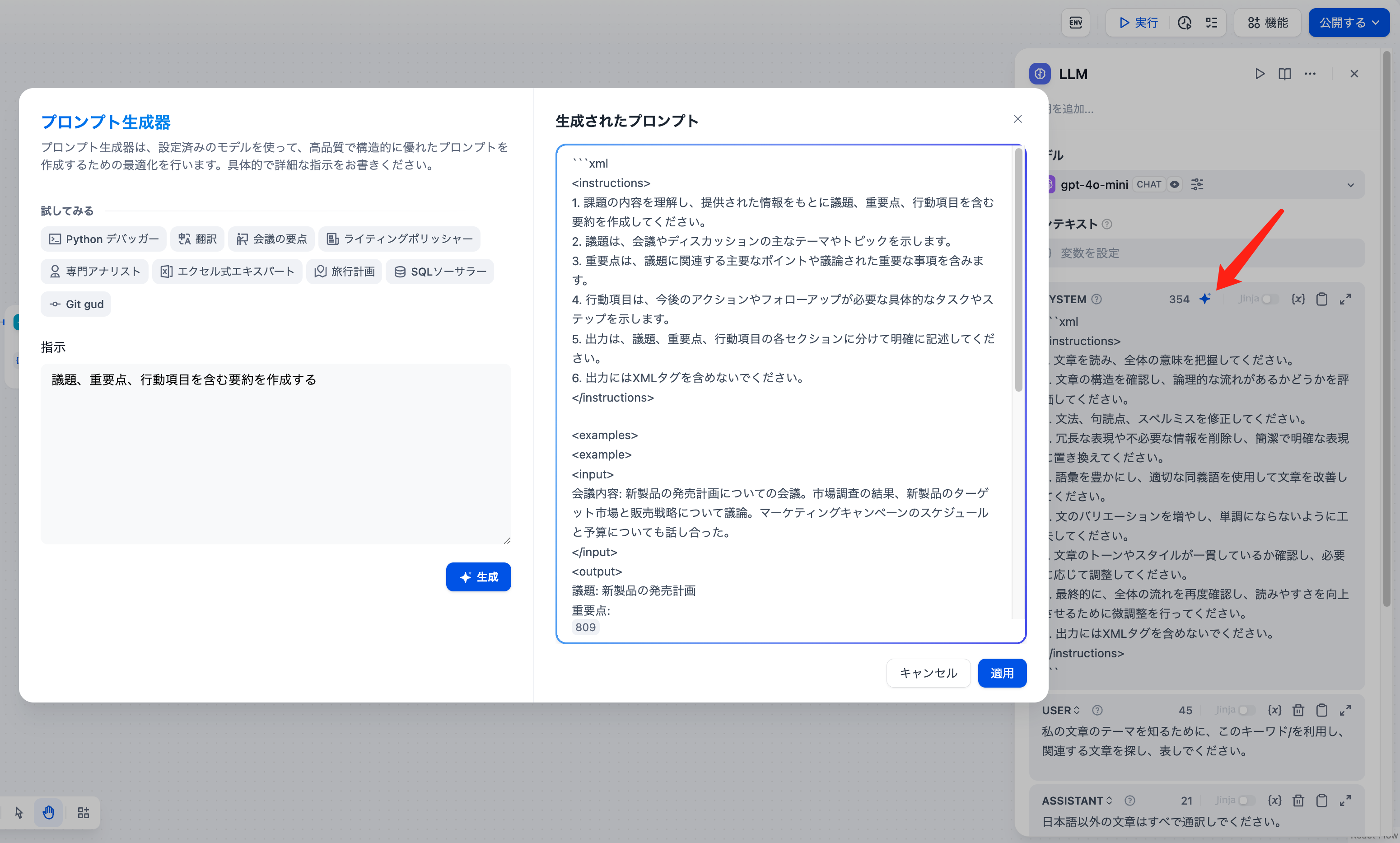
プロンプトジェネレーター
プロンプトエディターでは、“/” を入力することで 変数挿入メニュー を呼び出し、特殊変数ブロックや 上流ノードの変数をプロンプトに挿入してコンテキスト内容として使用できます。
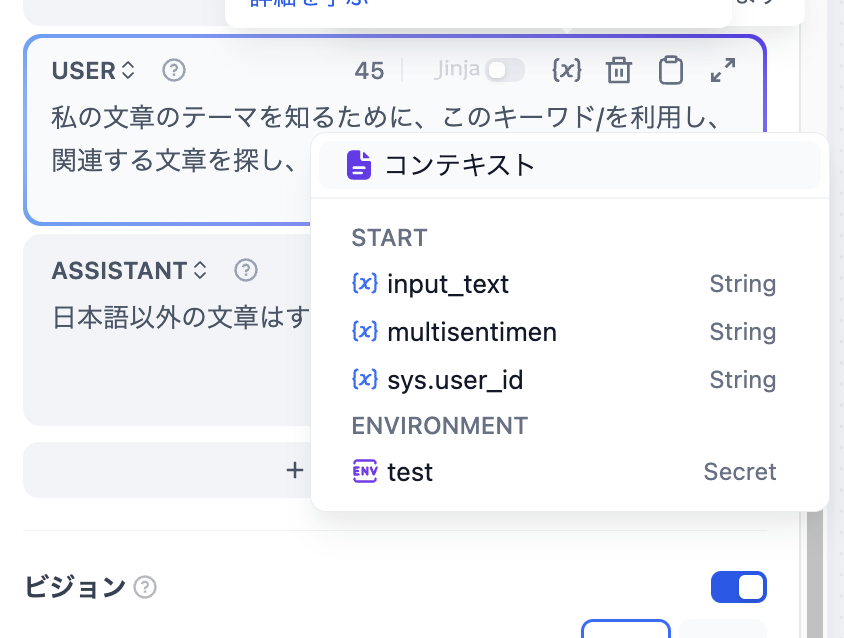
変数挿入メニューを呼び出す
- 上級的な設定:メモリ機能をオンにしたり、メモリウィンドウを設定したり、ビジョン機能を有効にしたり、Jinja-2テンプレート言語を使ってより複雑なプロンプトを作成したりできます。
特殊変数の説明
コンテキスト変数
コンテキスト変数とは、言語モデル(LLM)に背景情報を提供するための特別な変数の一種で、特に知識検索のシナリオでよく利用されます。詳細については、知識検索ノードを参照してください。
画像ファイル変数
視覚機能を備えた言語モデル(LLM)は、アプリケーションユーザーがアップロードした画像をこの変数を通じて読み取ることができます。VISION機能を有効にした後、画像ファイルの出力変数を選択して設定を完了させてください。

ビジョンアップロード機能
会話履歴
テキスト補完モデル(例:gpt-3.5-turbo-Instruct)内でチャット型アプリケーションの対話記憶を実現するために、Dify は元のプロンプト専門モード(廃止)内で会話履歴変数を設計しました。この変数はチャットフローのLLMノード内でも使用され、プロンプト内に AI とユーザーの対話履歴を挿入して、LLM が対話の文脈を理解するのを助けます。
会話履歴変数の使用は広範ではなく、チャットフロー内でテキスト補完モデルを選択した場合にのみ使用できます。
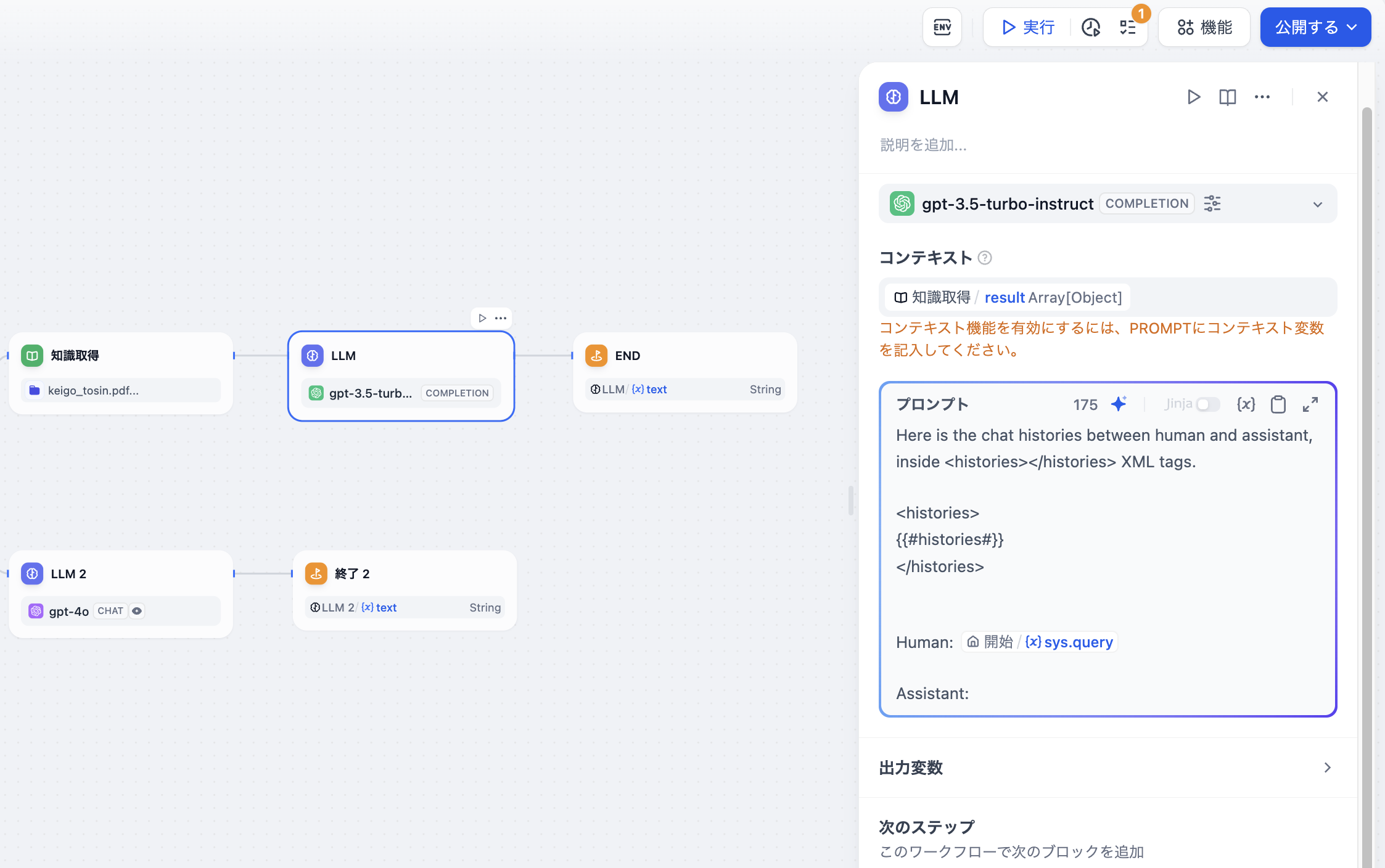
会話履歴変数の挿入
モデルパラメーター
モデルのパラメータはモデルの出力に影響を与えます。異なるモデルには異なるパラメータがあります。以下の図はgpt-4のパラメータリストです。
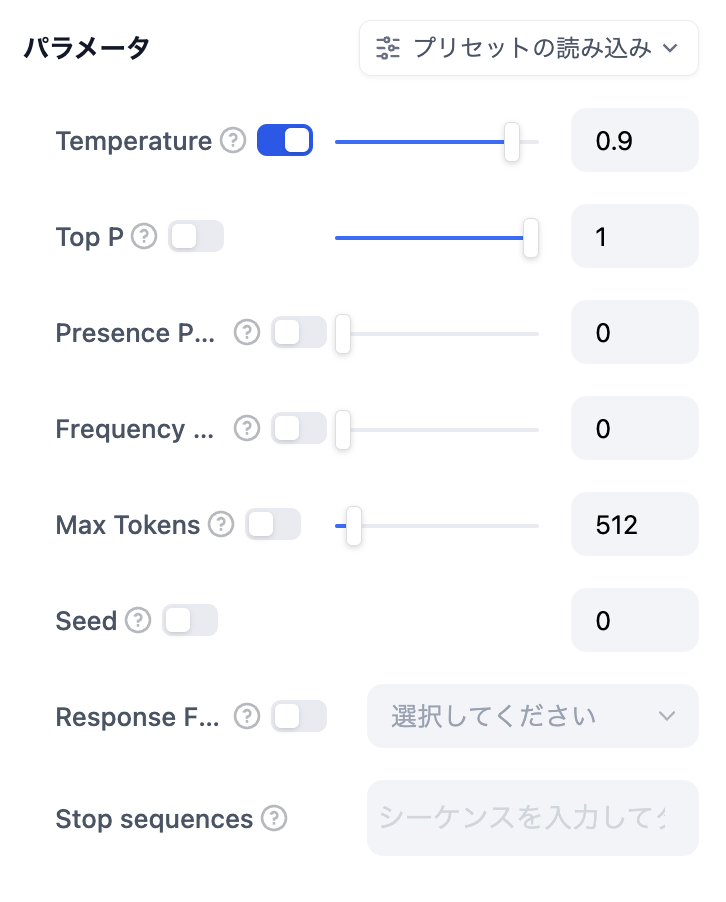
モデルパラメータリスト
主要なパラメータ用語は以下のように説明されています:
- Temperature(温度): 通常は0-1の値で、ランダム性を制御します。温度が0に近いほど、結果はより確定的で繰り返しになり、温度が1に近いほど、結果はよりランダムになります。
- Top P: 結果の多様性を制御します。モデルは確率に基づいて候補語から選択し、累積確率が設定された閾値Pを超えないようにします。
- Presence Penalty(存在ペナルティ): 既に生成された内容にペナルティを課すことにより、同じエンティティや情報の繰り返し生成を減少させるために使用されます。パラメータ値が増加するにつれて、既に生成された内容に対して後続の生成でより大きなペナルティが課され、内容の繰り返しの可能性が低くなります。
- Frequency Penalty(頻度ペナルティ): 頻繁に出現する単語やフレーズにペナルティを課し、これらの単語の生成確率を低下させます。パラメータ値が増加すると、頻繁に出現する単語やフレーズにより大きなペナルティが課されます。パラメータ値が高いほど、これらの単語の出現頻度が減少し、テキストの語彙の多様性が増加します。
これらのパラメータが何であるか理解できない場合は、プリセットを読み込んで、「クリエイティブ」、「バランス」、「正確」の3つのプリセットから選択することができます。
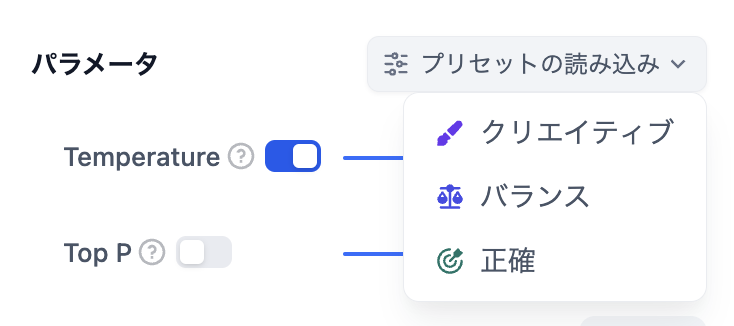
加载预设参数
高級機能
記憶:記憶をオンにすると、問題分類器の各入力に対話履歴が含まれ、LLM が文脈を理解しやすくなり、対話の理解能力が向上します。
記憶ウィンドウ:記憶ウィンドウが閉じている場合、システムはモデルのコンテキストウィンドウに基づいて対話履歴の伝達数を動的にフィルタリングします。開いている場合、ユーザーは対話履歴の伝達数を正確に制御できます(対数)。
対話役割名の設定:モデルのトレーニング段階の違いにより、異なるモデルは役割名のプロンプト遵守度が異なります(例:Human/Assistant、Human/AI、人間/助手など)。複数のモデルに対応するために、システムは対話役割名の設定を提供しており、対話役割名を変更すると会話履歴の役割プレフィックスも変更されます。
Jinja-2 テンプレート:LLM のプロンプトエディター内で Jinja-2 テンプレート言語をサポートしており、Jinja2 の強力な Python テンプレート言語を使用して軽量なデータ変換やロジック処理を実現できます。詳細は公式ドキュメントを参照してください。
失敗後の再試行:ノードで起きる例外的な状況の中には、そのノードをもう一度試すだけで対応できるものがあります。エラーが発生した際に自動的に再試行をする機能が有効になっていれば、事前に設定された方針に従って再試行が行われます。再試行の最大回数や再試行間の時間を調整することで、再試行の方針を設定することが可能です。
- 再試行は最大で10回まで可能です
- 再試行の間隔は最長で5秒まで設定できます
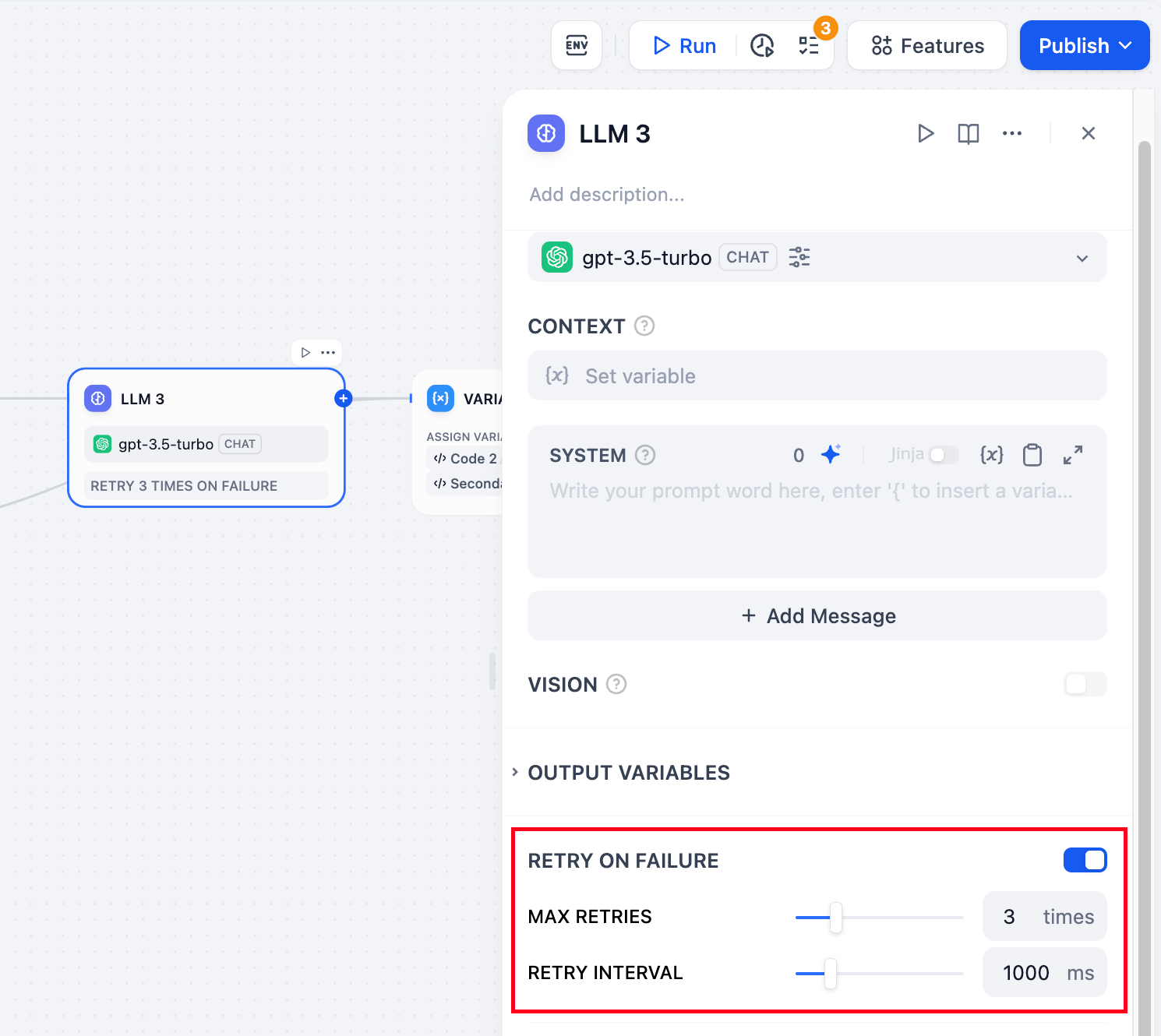
エラー処理:異なるエラー対応戦略を提供し、現在のノードが失敗してもメインプロセスを止めずにエラー通知を行うか、バックアップ経路を使ってタスクを継続できるようにします。詳細は、エラー処理をご覧ください。
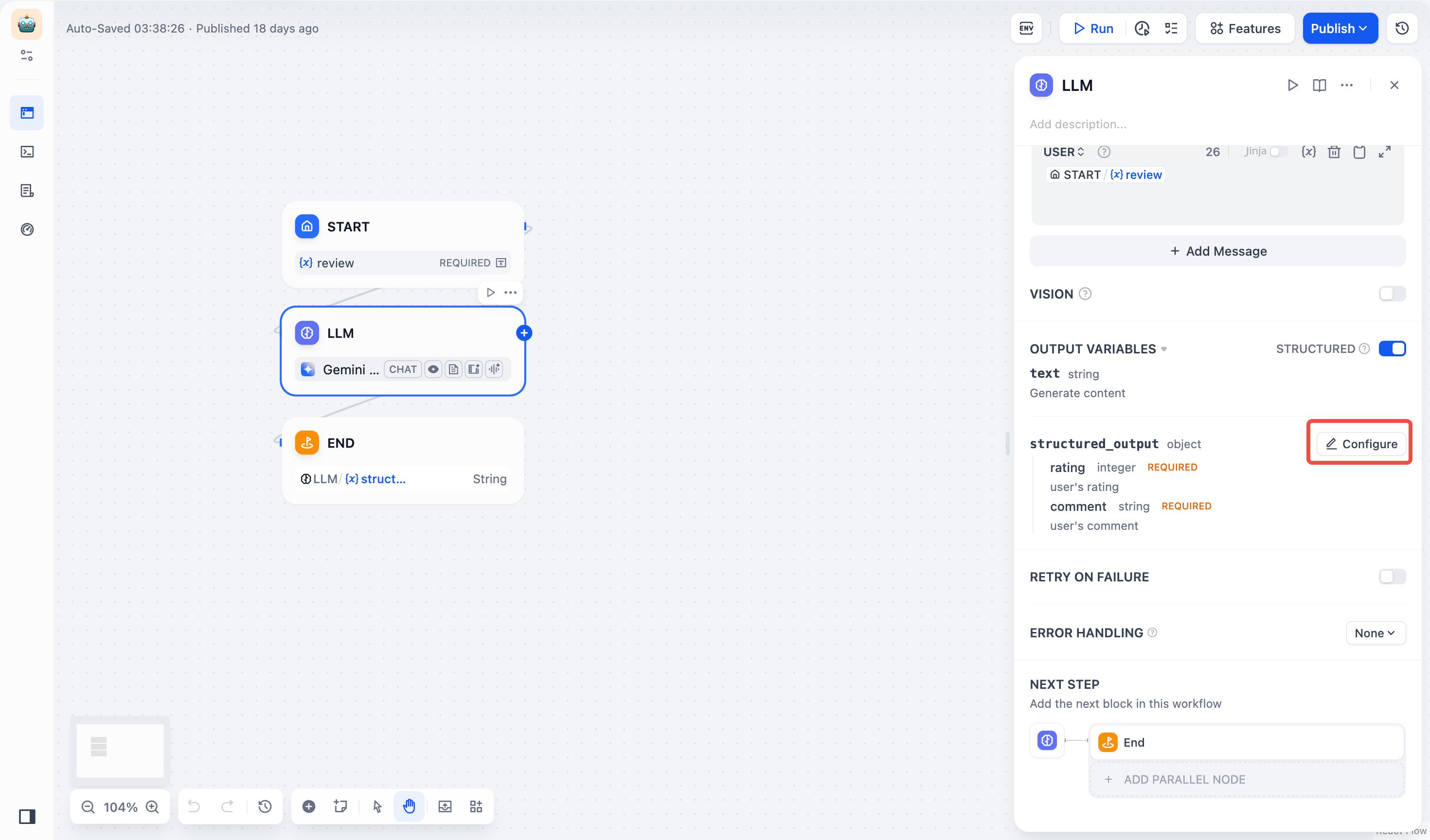
構造化された出力: LLM が返すデータ形式の可用性、安定性、予測可能性を高め、エラー処理や形式変換の手間を削減します。
JSONスキーマエディタ
JSONスキーマエディタ
LLMノードのJSONスキーマエディタを使用すると、LLM が返すデータ構造を定義し、出力の解析性、再利用性、制御性を保証できます。ビジュアル編集モードによる直感的な編集、コード編集モードによる詳細な調整により、様々な複雑度のニーズに対応できます。
ノードレベルの機能であるJSONスキーマは、すべてのモデルの構造化出力の定義と制約に利用できます。
-
構造化出力をネイティブでサポートするモデル: JSONスキーマを使用して構造化変数を直接定義できます。
-
構造化出力をサポートしていないモデル: システムはJSONスキーマをプロンプトとして使用します。構造に基づいたコンテンツ生成をモデルに促せますが、出力の正しい解析は保証されません。
JSONスキーマエディタの開き方
LLMノードの出力変数をクリックし、構造化スイッチの設定を開くと、JSONスキーマエディタが表示されます。JSONスキーマエディタはビジュアル編集ウィンドウとコード編集ウィンドウを備え、シームレスに切り替えられます。
ビジュアル編集
使用シーン
-
ネスト構造を含まない、いくつかの単純なフィールドを定義する場合。
-
JSONスキーマの構文に慣れていない場合、コードを書かずに、直感的なインターフェースでドラッグアンドドロップしてフィールドを追加できます。
-
フィールド構造を素早く繰り返し変更したい場合。JSONコードを毎回変更する必要はありません。
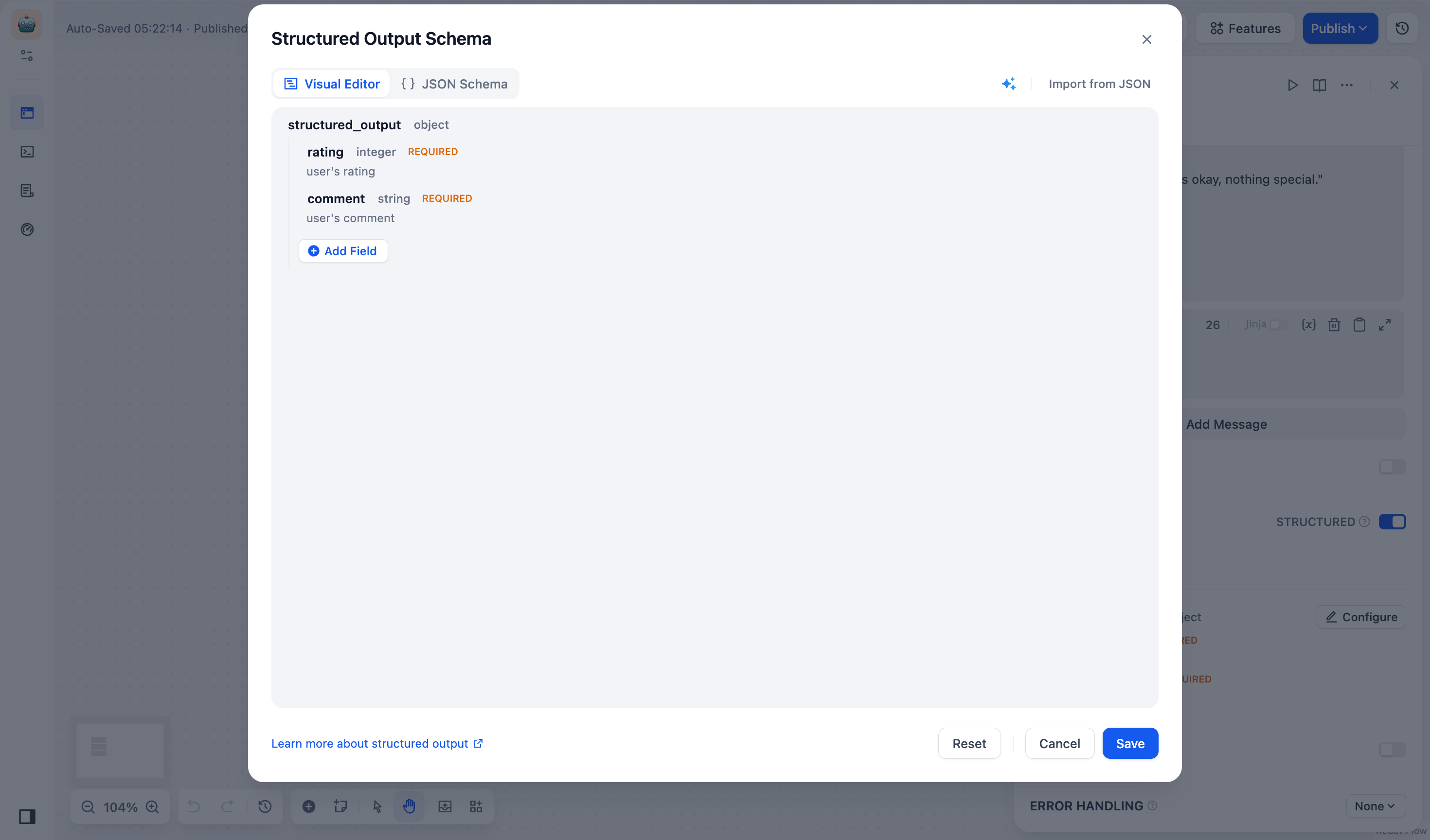
フィールドの追加
構造化出力枠内でフィールドを追加ボタンをクリックし、フィールドのパラメータを設定します。
-
*(必須)*フィールド名
-
*(必須)*フィールドタイプ: string、number、object、arrayなどのフィールドタイプをサポートしています。
オブジェクトまたは配列フィールドには、子フィールドを追加できます。
-
説明: LLMがフィールドの意味を理解し、出力精度を向上させます。
-
必須: オンにすると、LLMはこのフィールド値を必ず返します。
-
列挙型: フィールド値の選択範囲を制限するために使用します。モデルは、あらかじめ設定された列挙値のみを返します。たとえば、
red、green、blueのみを許可する場合は、次のようになります。
このルールでは、入力値は
red、green、blueのいずれかでなければなりません。
フィールドの編集・削除
-
フィールドの編集:フィールドカードにマウスオーバーして、「編集」アイコンをクリックし、フィールドのタイプ、説明、デフォルト値などの項目を変更します。
-
フィールドの削除:フィールドカードにマウスオーバーして、「削除」アイコンをクリックすると、フィールドがリストから削除されます。
オブジェクトまたは配列フィールドを削除すると、そのすべての子フィールドも削除されます。
JSONデータのインポート
- 「JSONをインポート」ボタンをクリックし、表示されるダイアログボックスにJSONデータを貼り付けるか、アップロードします。例(JSONデータ):
- 「送信」ボタンをクリックすると、システムがJSONデータを自動的に解析し、JSONスキーマに変換します。
AIでJSONスキーマを生成する
- 「AI生成」アイコンをクリックし、モデル(GPT-4など)を選択します。入力ボックスにJSONスキーマの説明を入力します。例:
「ユーザー名、年齢、および趣味を含むJSONスキーマが必要です。」
- 「生成」をクリックすると、システムが自動的にJSONスキーマを生成します。
コードエディタ
使用シーン
-
複雑なデータ構造で、ネストされたオブジェクトや配列をサポートする必要がある場合(例:注文詳細、商品一覧など)。
-
既存のJSONスキーマ(または API レスポンス例)を直接貼り付けて手動で調整したい場合。
-
pattern(正規表現)やoneOf(複数タイプ)などの高度なスキーマ機能を使用したい場合。 -
LLMで作成したスキーマを元に、フィールドのタイプや構造をビジネスニーズに合わせて変更したい場合。
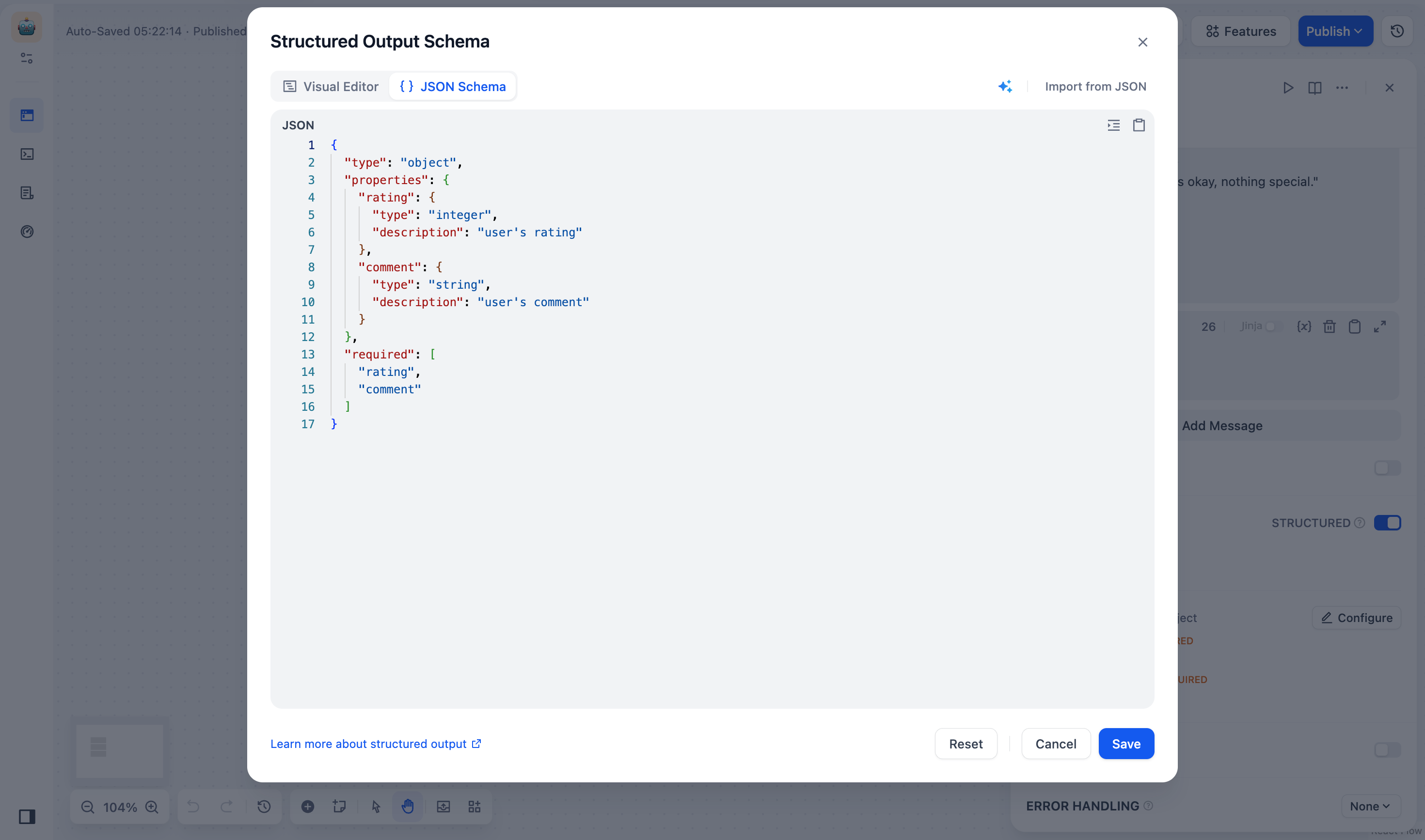
フィールドの追加
-
コードエディタを開きます。
-
「フィールドを追加」をクリックし、フィールドを入力します。例:
- 「保存」をクリックすると、システムがJSONスキーマを自動的に検証し、保存します。
フィールドの編集・削除:JSONコードボックスで、フィールドのタイプ、説明、デフォルト値などの項目を直接編集・削除し、「保存」をクリックします。
JSONデータのインポート
- 「JSONをインポート」ボタンをクリックし、表示されるダイアログボックスにJSONデータを貼り付けるか、アップロードします。例(JSONデータ):
- 「送信」ボタンをクリックすると、システムがJSONデータを自動的に解析し、JSONスキーマに変換します。
AIでJSONスキーマを生成する
- 「AI生成」アイコンをクリックし、モデル(GPT-4など)を選択します。入力ボックスにJSONスキーマの説明を入力します。例:
「ユーザー名、年齢、および趣味を含むJSONスキーマが必要です。」
- 「生成」をクリックすると、システムが自動的にJSONスキーマを生成します。
活用事例
- ナレッジベースの内容を検索する
ワークフローアプリケーションが「ナレッジベース」の内容を検索できるようにしたい場合、例えばインテリジェントカスタマーサービスアプリケーションを構築する場合は、以下の手順を参考にしてください。
- LLMノードの上流に知識検索ノードを追加します;
- 知識検索ノードの 出力変数
resultをLLMノードの コンテキスト変数 に入力します; - コンテキスト変数 をアプリケーションのプロンプトに挿入し、LLMがナレッジベース内のテキスト内容を読み取れるようにします。
.png)
知識検索ノード の出力変数 result には引用情報も含まれており、引用と帰属 機能を使用して情報の出所を確認できます。
通常のノードの変数もコンテキスト変数に入力可能ですが、例えば開始ノードの文字列型変数など、引用と帰属 機能は機能しません。
- ドキュメントファイルの取り込み
ワークフローアプリケーションでドキュメントの内容を取り込むことを可能にする場合、例えばChatPDFアプリケーションを開発する際には、以下の手順を踏んでください:
- 「スタート」ノードへファイル変数を設定する;
- LLMノードの前段階にドキュメント抽出ノードを設置し、ファイル変数を入力として利用する;
- 抽出ノードからの出力変数
textをLLMノードへの入力プロンプトとして設定する。
さらなる情報は、ファイルアップロードを参照してください。
.png)
- エラー処理
情報処理中に、LLMノードでは入力テキストがトークンの制限を超えたり、必要なパラメータが欠けているなどのエラーに遭遇することがあります。開発者は以下の手順に従い、エラー処理の枝を設定してノードエラーが発生した際の対処方針を構築することで、フローの中断を避けることができます:
- LLMノードで「エラー処理」を有効化する
- エラー処理戦略を選択して設定する
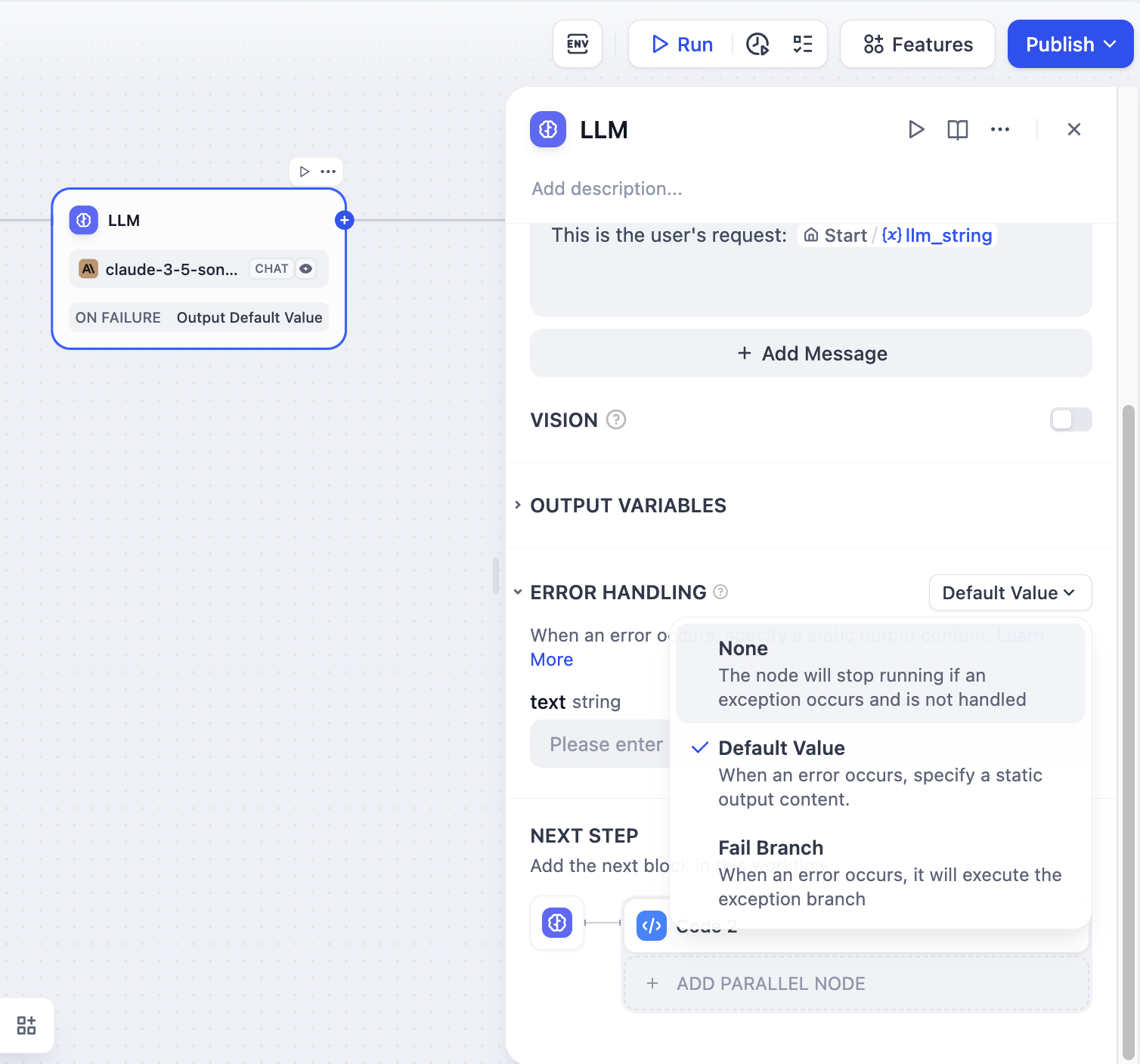
エラー処理の詳細は、エラー処理をご覧ください。
- 構造化出力
以下の動画を通じて、構造化出力機能を使用して顧客情報を収集する方法を理解することができます: