

ノードの説明
パラメータ抽出
定義
大規模言語モデル(LLM)を利用して自然言語から推論し、構造化パラメータを抽出し、ツール呼び出しやHTTPリクエストに用いる。
Difyワークフロー内には豊富なツールが用意されており、その多くは構造化パラメータを入力として要求します。パラメータ抽出器は、ユーザーの自然言語をツールが認識できるパラメータに変換し、ツールの呼び出しを容易にします。
ワークフロー内の一部のノードは特定のデータ形式を入力として要求します。例えばイテレーションノードの入力は配列形式である必要があり、パラメータ抽出器は構造化パラメータの変換を容易に実現します。
シナリオ
- 自然言語からツールが必要とするキー・パラメーターを抽出する例として、簡単な対話形式のArxiv論文検索アプリを構築する場合を考えます。
この例では、Arxiv論文検索ツールの入力パラメータとして「論文の著者」または「論文番号」が要求されます。パラメータ抽出器は「この論文の内容は何ですか:2405.10739」という質問から論文番号2405.10739を抽出し、ツールのパラメータとして正確に検索します。
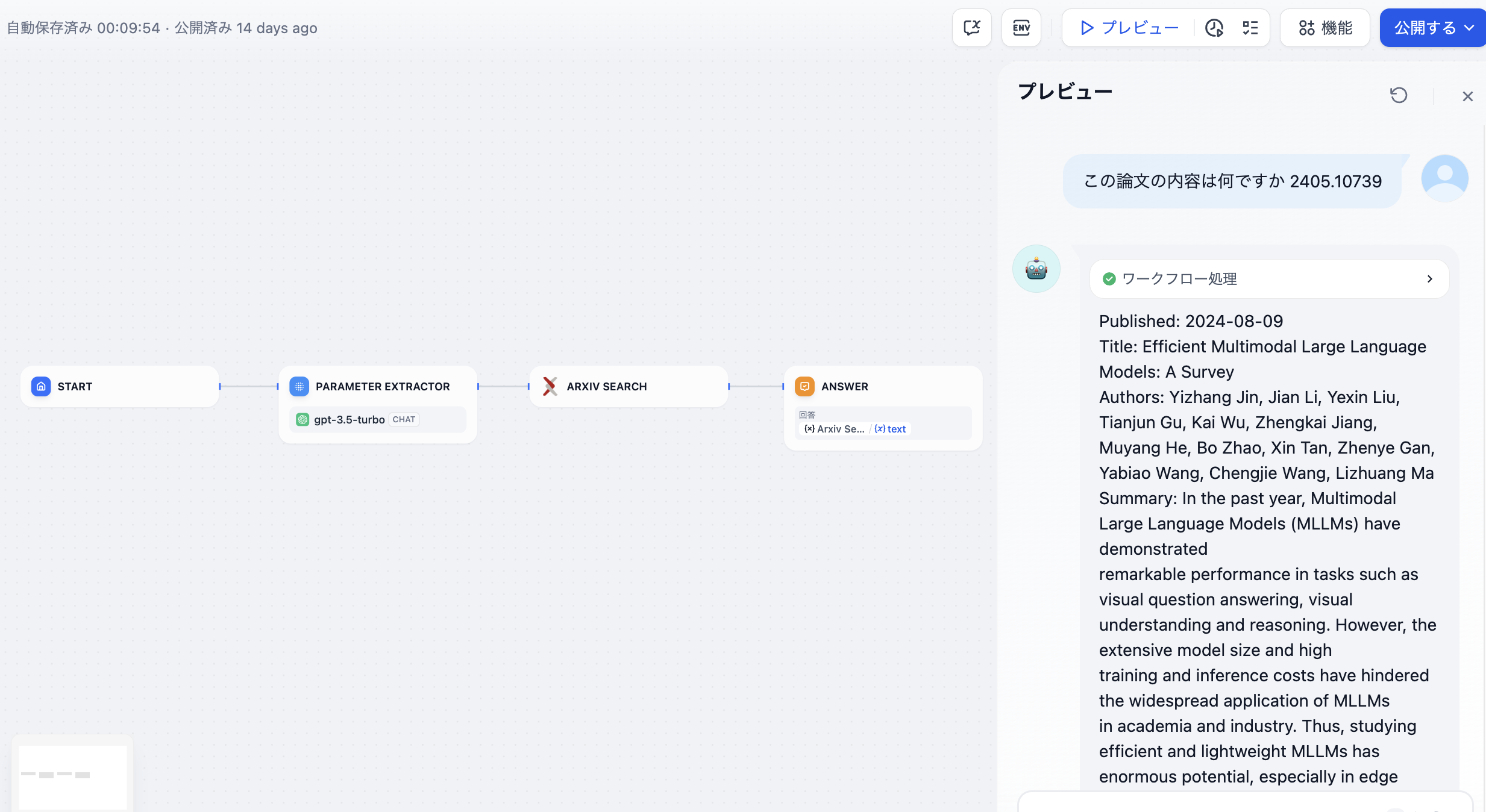
Arxiv論文検索ツール
- テキストを構造化データに変換する例として、長い物語のイテレーション生成アプリの前工程として、テキスト形式の章内容を配列形式に変換し、イテレーションノードでのマルチラウンド生成処理を容易にします。
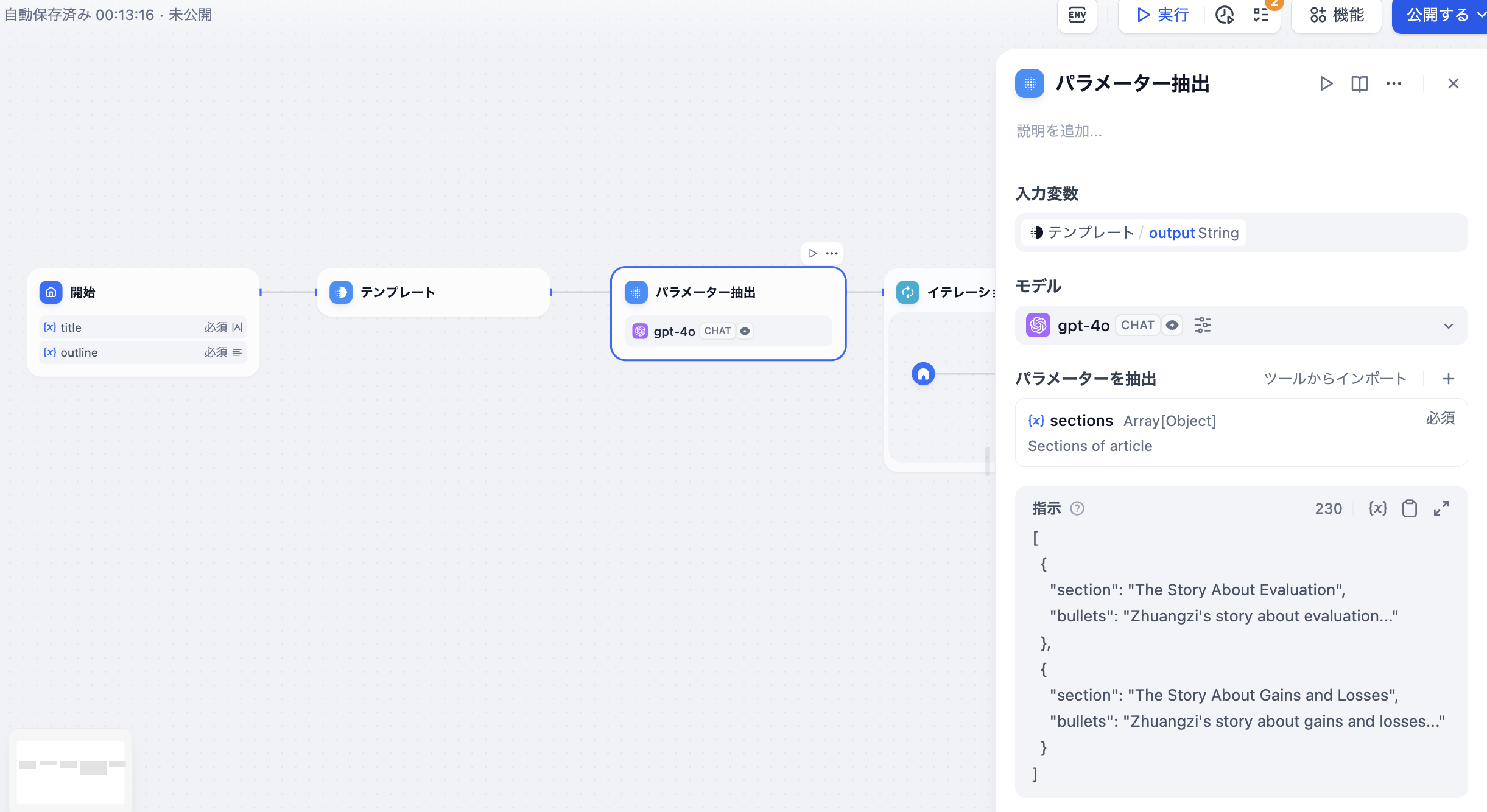
テキストを構造化データに変換する
- 構造化データを抽出してHTTPリクエストを使用することで、任意のアクセス可能なURLにリクエストを送信し、外部検索結果の取得やウェブフック、画像生成などのシナリオに適用できます。
設定方法
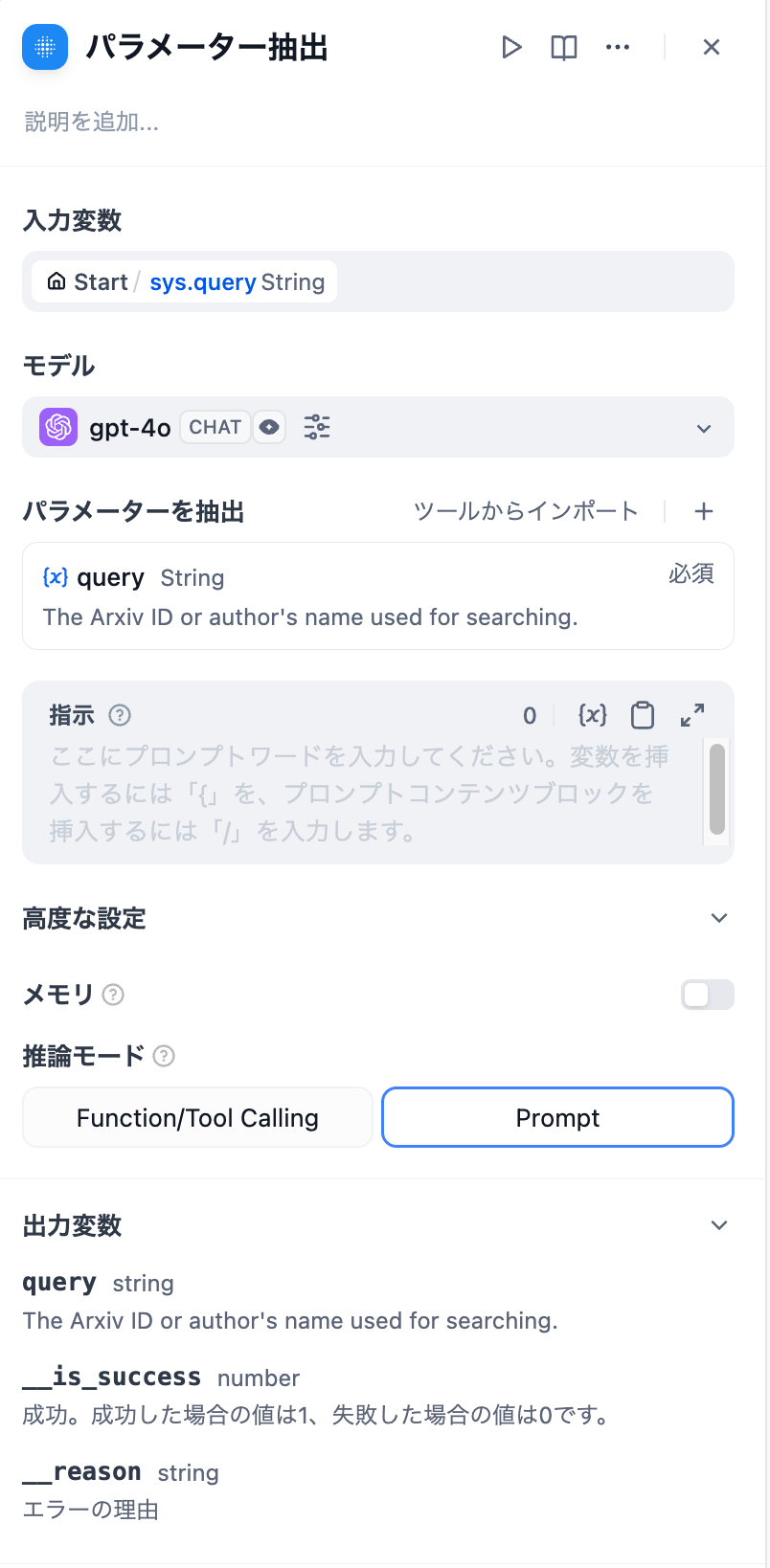
パラメータ抽出の設定
設定手順
- 入力変数を選択。通常はパラメータ抽出のための変数入力を選びます。ファイルタイプもサポートします。
- モデルを選択。パラメータ抽出器の抽出はLLMの推論と構造化生成能力に依存します。
- 抽出パラメータを定義。必要なパラメータを手動で追加するか、既存のツールから簡単にインポートできます。
- コマンド作成。複雑なパラメータの抽出時には、例を作成することでLLMの生成効果と安定性を向上させることができます。
高度な設定
推論モード
一部のモデルは関数/ツール呼び出しや純プロンプトの方法でパラメータ抽出を実現する2つの推論モードをサポートしており、コマンドの遵守能力に違いがあります。例えば、あるモデルが関数呼び出しに不向きな場合、プロンプト推論に切り替えることができます。
- Function Call/Tool Call
- プロンプト
メモリ
メモリを有効にすると、問題分類器の各入力にチャット履歴が含まれ、LLMが前文を理解し、対話の中での問題理解能力を向上させます。
画像
画像をオープンする。
出力変数
- 定義された変数を抽出
- ノード組み込み変数
__is_success 数値 抽出が成功した場合は1、失敗した場合は0となります。
__reason 文字列 抽出エラーの原因