

事前準備
この記事を読む前に、ナレッジパイプラインのプロセスに関する基本的な理解と、プラグイン開発に関する一定の知識があることを確認してください。関連する内容は、以下のドキュメントで確認できます:データソースプラグインのタイプ
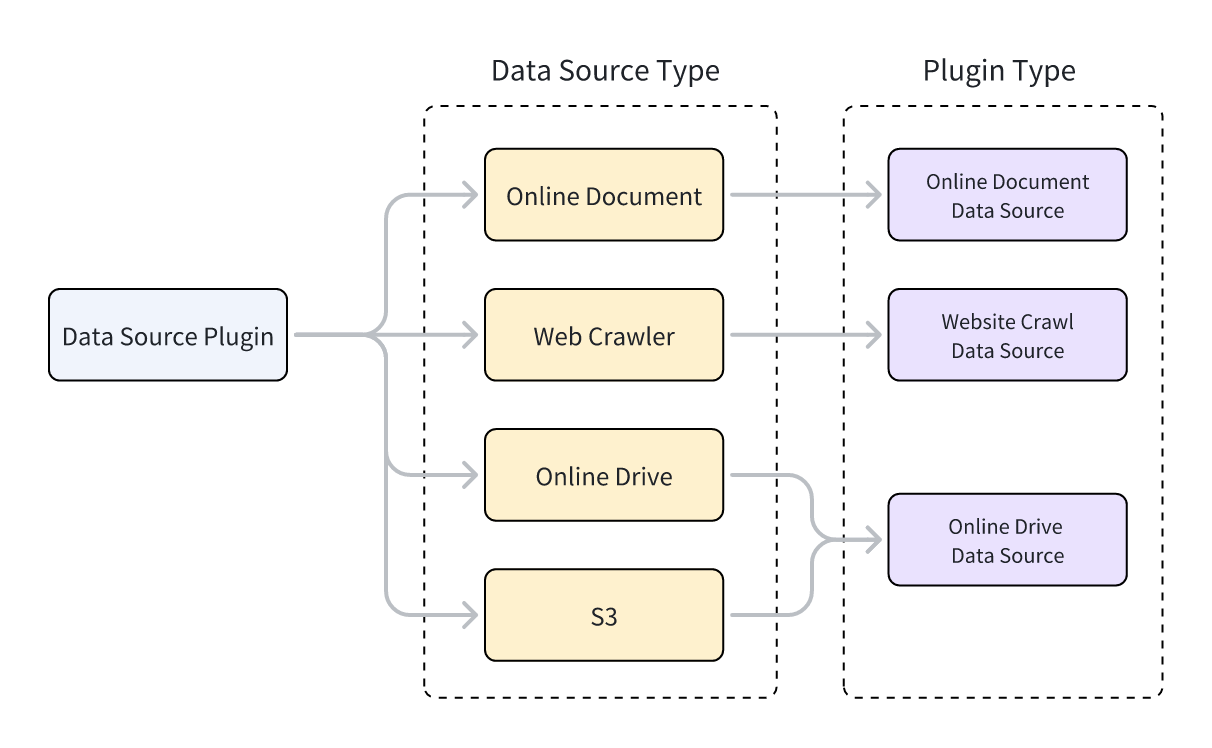
Difyは、Webクローラー、オンラインドキュメント、オンラインストレージの3種類のデータソースプラグインをサポートしています。プラグインのコードを具体的に実装する際には、プラグイン機能を実現するクラスが異なるデータソースクラスを継承する必要があります。3つのプラグインタイプは、3つの親クラスに対応しています。親クラスを継承してプラグイン機能を実現する方法については、 Dify プラグイン開発:Hello World ガイド-4.4 ツール (Tool) ロジックの実装をお読みください。。
- Webクローラー:Jina Reader、FireCrawl
- オンラインドキュメント:Notion、Confluence、GitHub
- オンラインストレージ:Onedrive、Google Drive、Box、AWS S3、Tencent COS
プラグインの開発
データソースプラグインの作成
スキャフォールディングのコマンドラインツールを使用して、データソースプラグインを作成し、datasource タイプを選択できます。設定が完了すると、コマンドラインツールが自動的にプラグインのプロジェクトコードを生成します。
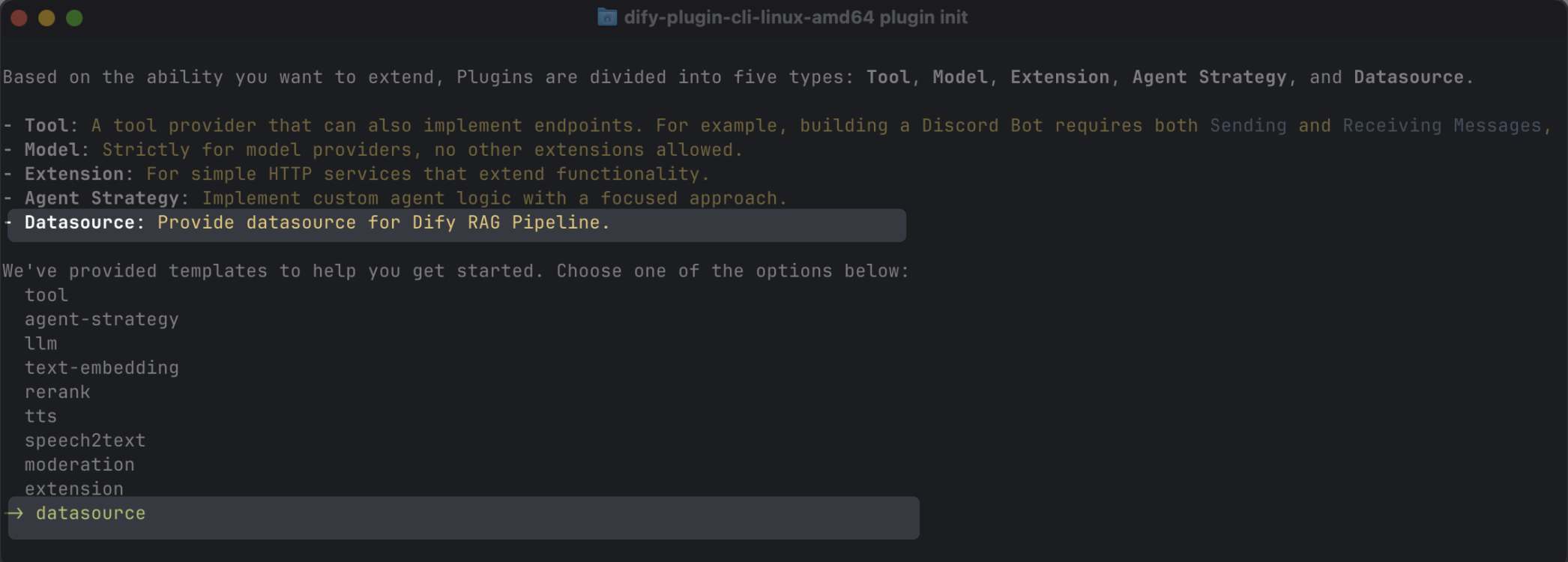
通常、データソースプラグインはDifyプラットフォームの他の機能を使用しないため、追加の権限を設定する必要はありません。
データソースプラグインの構造
データソースプラグインは、主に3つの部分で構成されています。manifest.yamlファイル:プラグインの基本情報を記述しますproviderディレクトリ:プラグインプロバイダーの説明と認証を実装するコードが含まれますdatasourcesディレクトリ:データソースを取得するコアロジックを実装する説明とコードが含まれます
正しいバージョンとタグの設定
-
manifest.yamlファイルでは、プラグインがサポートするDifyの最低バージョンを次のように設定する必要があります: -
manifest.yamlファイルで、プラグインに以下のデータソースタグを追加し、プラグインがDify Marketplaceでデータソースとして分類・表示されるようにする必要があります: -
requirements.txtファイルでは、プラグイン開発に使用するプラグインSDKのバージョンを次のように設定する必要があります:
プロバイダーの追加
プロバイダーYAMLファイルの作成
プロバイダーYAMLファイルの定義と記述は、ツールプラグインと基本的に同じですが、以下の2点のみ異なります。プロバイダーYAMLファイルの作成に関する詳細については、Dify プラグイン開発:Hello World ガイド-
4.3 プロバイダー認証情報の設定をお読みください。
データソースプラグインは、OAuth 2.0 または API キーの2つの方法で認証をサポートしています。OAuth の設定方法については、ツールプラグインに OAuth サポートを追加するをお読みください。
プロバイダーコードファイルの作成
-
APIキー認証モードを使用する場合、データソースプラグインのプロバイダーコードファイルはツールプラグインと完全に同じですが、プロバイダークラスが継承する親クラスを
DatasourceProviderに変更するだけで済みます。 -
OAuth認証モードを使用する場合、データソースプラグインはツールプラグインと若干異なります。OAuthを使用してアクセス権限を取得する際、データソースプラグインは同時にユーザー名とアバターを返し、フロントエンドに表示することができます。そのため、
_oauth_get_credentialsと_oauth_refresh_credentialsは、name、avatar_url、expires_at、およびcredentialsを含むDatasourceOAuthCredentials型を返す必要があります。-
DatasourceOAuthCredentialsクラスの定義は以下の通りです。返す際には対応する型に設定する必要があります: -
_oauth_get_authorization_url、_oauth_get_credentials、および_oauth_refresh_credentialsの関数シグネチャは以下の通りです:- _oauth_get_credentials
- _oauth_refresh_credentials
-
データソースの追加
3種類のデータソースプラグインでは、作成するYAMLファイル形式とデータソースコード形式が異なります。以下でそれぞれ説明します。Webクローラー(Web Crawler)
Webクローラー系プラグインのプロバイダーYAMLファイルでは、output_schema は source_url、content、title、description の4つのパラメータを固定で返す必要があります。
WebsiteCrawlDatasource クラスを継承し、_get_website_crawl メソッドを実装した上で、create_crawl_message メソッドを使用してウェブクローラーメッセージを返す必要があります。
複数のウェブページをクロールし、バッチで返す必要がある場合は、WebSiteInfo.status を processing に設定し、create_crawl_message メソッドを使用して各バッチのWebクローラーメッセージを返すことができます。すべてのウェブページのクロールが完了したら、WebSiteInfo.status を completed に設定します。
オンラインドキュメント(Online Document)
オンラインドキュメント系プラグインの戻り値には、ドキュメントの内容を表すcontent フィールドを少なくとも含める必要があります。以下に例を示します。
OnlineDocumentDatasource クラスを継承し、_get_pages と _get_content の2つのメソッドを実装する必要があります。ユーザーがプラグインを実行すると、まず _get_pages メソッドを介してドキュメントリストを取得します。ユーザーがリストから特定のドキュメントを選択すると、次に _get_content メソッドを介してドキュメントの内容を取得します。
- _get_pages
- _get_content
オンラインストレージ(Online Drive)
オンラインストレージ系プラグインの戻り値の型はファイルであり、以下の仕様に従う必要があります。OnlineDriveDatasource クラスを継承し、_browse_files と _download_file の2つのメソッドを実装する必要があります。
ユーザーがプラグインを実行すると、まず _browse_files メソッドを介してファイルリストを取得します。このとき prefix は空で、ルートディレクトリ直下のファイルリストを取得することを示します。ファイルリストには、フォルダとファイルの2種類の変数が含まれます。ユーザーがさらにフォルダを開くと、_browse_files メソッドが再度実行されます。このとき、OnlineDriveBrowseFilesRequest の中の prefix はフォルダIDとなり、そのフォルダ内のファイルリストを取得するために使用されます。
ユーザーが特定のファイルを選択すると、プラグインは _download_file メソッドとファイルIDを介してファイルの内容を取得します。_get_mime_type_from_filename メソッドを使用してファイルのMIMEタイプを取得し、パイプラインで異なるファイルタイプに対して異なる処理を行うことができます。
ファイルリストに複数のファイルが含まれる場合、OnlineDriveFileBucket.is_truncated を True に設定し、OnlineDriveFileBucket.next_page_parameters をファイルリストの取得を続行するためのパラメータ(例えば、次のページの要求IDやURLなど、サービスプロバイダーによって異なります)に設定することができます。
- _browse_files
- _download_file
prefix、bucket、id の各変数に特別な使用方法があり、実際の開発では必要に応じて柔軟に適用できます。
prefix: ファイルパスのプレフィックスを表します。例えば、prefix=container1/folder1/は、container1バケット内のfolder1フォルダにあるファイルまたはファイルリストを取得することを示します。bucket: ファイルバケットを表します。例えば、bucket=container1は、container1バケット直下のファイルまたはファイルリストを取得することを示します(非標準のS3プロトコルのオンラインストレージの場合、このフィールドは空にすることができます)。id:_download_fileメソッドは prefix 変数を使用しないため、ファイルパスを id に連結する必要があります。例えば、id=container1/folder1/file1.txtは、container1バケット内の folder1 フォルダにあるfile1.txtファイルを取得することを示します。
プラグインのデバッグ
データソースプラグインは、リモートデバッグとローカルプラグインとしてのインストールの2つのデバッグ方法をサポートしています。注意点:- プラグインがOAuth認証モードを使用している場合、リモートデバッグ時の
redirect_uriはローカルプラグインの設定と一致しないため、サービスプロバイダーのOAuth App関連設定を変更する必要があります。 - データソースプラグインはステップ実行デバッグをサポートしていますが、機能の正確性を保証するため、完全なナレッジパイプラインでテストすることをお勧めします。
最終チェック
パッケージ化して公開する前に、以下の項目がすべて完了していることを確認してください:- サポートする最低Difyバージョンを
1.9.0に設定する - SDKバージョンを
dify-plugin>=0.5.0,<0.6.0に設定する README.mdとPRIVACY.mdファイルを作成する- コードファイルには英語のコンテンツのみが含まれていることを確認する
- デフォルトのアイコンをデータソースプロバイダーのロゴに置き換える
パッケージ化と公開
プラグインディレクトリで以下のコマンドを実行すると、.difypkg プラグインパッケージが生成されます:
- あなたのDify環境にプラグインをインポートして使用する
- プルリクエストを送信して、Dify Marketplaceにプラグインを公開する
プラグインの公開プロセスについては、プラグインのリリース。
このページを編集する | 問題を報告する